
The goal of this work was to design and assess a locally deployable LLM-based clinical assistant using de-identified EHR data for training and public benchmarks for evaluation. I conducted no clinical, prospective, or user studies. All experiments are single-modal (text). Imaging and other multimodal inputs are outside scope.
Methodological contributions and scope
This work documents: (1) a patient-timeline construction procedure that restructures de-identified EHR notes into temporally indexed snapshots suitable for supervised instruction tuning; (2) a retrieval pipeline grounded in open medical references and integrated into prompting for answer grounding; (3) a locally deployable inference stack (quantized model + OpenAI-compatible API) that interoperates with EHR retrieval; and (4) ablation experiments and error analysis isolating the contributions of fine-tuning and RAG.
This paper evaluates the end-to-end system under multiple configurations (with and without RAG) and a deterministic protocol. (Fig. 1)
AIDx-Copilot training and implementation
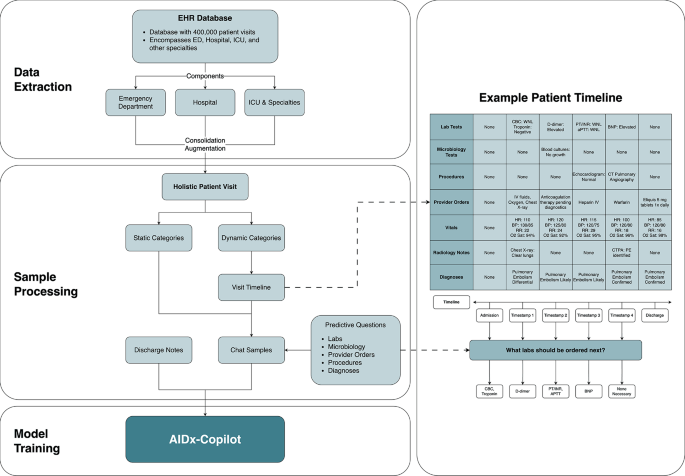 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Data processing pipeline for preparing supervised training data for AIDx-Copilot. De-identified EHR records from emergency, inpatient, and ICU settings are consolidated into a holistic visit representation. Static attributes (e.g., demographics, history) and dynamic attributes (e.g., labs, orders, diagnoses) are separated, and dynamic events are organized into temporally ordered visit timelines. Timeline snapshots are used to generate predictive question–answer pairs for instruction tuning. The patient timeline shown is illustrative and not a complete clinical record.
AIDx-Copilot was trained using de-identified clinical records derived from MIMIC-IV10,11,12. I consolidated records from emergency, inpatient, and intensive care settings to cover common hospital documentation patterns.
Data preparation and temporal alignment
Each patient chart was restructured into static attributes (demographics, chronic conditions, medical history) and dynamic attributes (laboratory results, orders, procedures, diagnoses). I generated visit timelines by appending a new “snapshot” when any dynamic field changed.
To reduce temporal leakage in supervised prediction (i.e., using future information to answer past queries), snapshot construction orders events by timestamp and generates questions from the current snapshot while sourcing supervision targets only from strictly later snapshots.
Chat sample generation
To simulate clinical query–response interactions, I generated synthetic dialogue pairs in which questions were derived from dynamic variables (e.g., “What does the next lab result show?”) and answers from subsequent timestamps. This yielded approximately eight million question–answer samples for supervised fine-tuning.
Model fine-tuning
The base model was Mixtral-8x7B-Instruct-v0.115. I fine-tuned it using Low-Rank Adaptation (LoRA)16 with DeepSpeed ZeRO optimizations17,18. Table 1 lists all training hyperparameters. Following training, LoRA weights were merged with the base model and quantized using ExLLaMA v219 to reduce memory footprint and enable fast inference.
Deployment stack
AIDx-Copilot is served behind an OpenAI-compatible API implemented with TabbyAPI20. The backend orchestrates EHR retrieval, optional retrieval grounding, and response generation. (Fig. 2)
Retrieval-augmented generation (RAG)
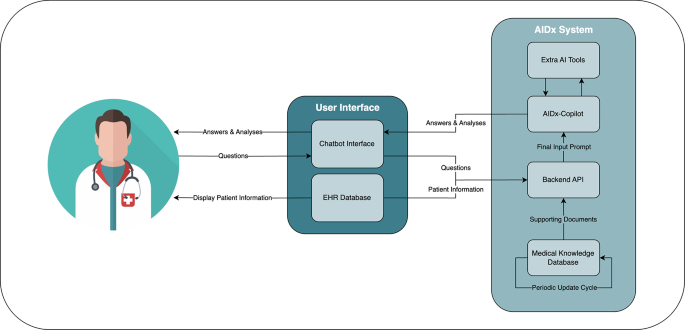 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Workflow of AIDx, illustrating integration with an EHR database and optional retrieval grounding from medical references before response generation.
To provide access to external medical reference material, AIDx supports retrieval-augmented generation (RAG)21. I constructed a reference database from open-access medical textbooks in the LibreTexts Medicine Library22. Text was chunked using a recursive splitter (chunk size 1,000 characters; no overlap) and indexed for similarity search. For background and terminology, I follow recent surveys of retrieval-augmented generation for LLMs23. Table 2 summarizes the RAG configuration.
Data-flow boundary and deployment modes
The reference implementation can embed text using OpenAI text-embedding-3-small and store vectors in Pinecone24. These choices may involve third-party services depending on deployment. For privacy-sensitive on-premises settings, an equivalent fully local configuration replaces the embedding model with a locally hosted BGE-base-en-v1.5 encoder and replaces the vector store with a self-hosted FAISS index. The application-layer interface (retrieve top passages, append to prompt) remains unchanged.
RAG usage in benchmark evaluation
To clearly delineate system components: the primary benchmark results reported in Table 3 were obtained without RAG. This means the primary benchmarks test the fine-tuned model in isolation and do not reflect retrieval grounding. Ablation experiments in Section 6.3 separately evaluate the effect of enabling RAG on benchmark performance.
Evaluation protocol
Evaluation used the MultiMedQA benchmark suite25. I loaded all benchmarks from the Open Life Science AI MultiMedQA collection on Hugging Face (https://huggingface.co/collections/openlifescienceai/multimedqa).
Dataset identifiers and revisions
To make the benchmark configuration unambiguous, I record the dataset repositories and the revision (Git commit on the main branch) used at the time of evaluation:
-
MedQA (USMLE): openlifescienceai/medqa @ 153e61c.
-
PubMedQA: openlifescienceai/pubmedqa @ 50fc41d.
-
MedMCQA: openlifescienceai/medmcqa @ c8b1a7c.
-
MMLU Clinical Knowledge: openlifescienceai/mmlu_clinical_knowledge @ e151167.
-
MMLU Professional Medicine: openlifescienceai/mmlu_professional_medicine @ a7a792b.
-
MMLU Anatomy: openlifescienceai/mmlu_anatomy @ a7a792b.
-
MMLU College Biology: openlifescienceai/mmlu_college_biology @ 94b1278.
-
MMLU College Medicine: openlifescienceai/mmlu_college_medicine @ d983527.
-
MMLU Medical Genetics: openlifescienceai/mmlu_medical_genetics @ f248e4a.
For each dataset and MMLU subject, I used the test split.
Prompt template
For each question, AIDx-Copilot received the prompt shown in Listing 1. The system message establishes the medical assistant role. The user message contains the question stem and answer options verbatim from the dataset. The formatting constraint restricts the model to outputting a single-letter answer.
Listing 1 Exact prompt template used for all benchmark evaluations. Placeholders question and options are filled from each dataset item. For RAG-enabled ablation runs, retrieved passages are prepended to the user message as shown in Section 3.5.
 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Decoding and scoring
For each question, AIDx-Copilot produced a single answer under deterministic decoding (temperature=0, top_p=1, repetition_penalty=1.0; no self-consistency voting, no chain-of-thought). A regular expression (BEST ANSWER:\(\backslash\)s*([A-D]) for four-option items; BEST ANSWER:\(\backslash\)s*([A-C]) for PubMedQA) extracted the predicted letter. Items where the regex failed to match were scored as incorrect. Accuracy was computed as exact match with the reference label.
Uncertainty reporting
For each dataset, I report a Wilson 95% confidence interval for accuracy to reflect uncertainty due to finite test set size.
Ablation study design
To isolate the contributions of EHR-based fine-tuning and retrieval grounding, I evaluated four configurations on the full MultiMedQA suite under the identical deterministic protocol described above:
-
1.
Base: Mixtral-8x7B-Instruct-v0.1 without fine-tuning or RAG. This is the unmodified base model with quantization applied identically to the fine-tuned variant.
-
2.
Base + RAG: Base model with retrieval grounding enabled. For each benchmark question, the question text was used as the retrieval query, and the top-5 passages from the LibreTexts Medicine index were prepended to the user message under the header “Reference context:”.
-
3.
Fine-tuned (FT): AIDx-Copilot after EHR-based fine-tuning, without RAG. This is the configuration reported in the primary results (Table 3).
-
4.
Fine-tuned + RAG (FT + RAG): AIDx-Copilot with retrieval grounding enabled using the same RAG procedure as configuration 2.
All four configurations used the same quantized inference stack, prompt template (with or without prepended context), and scoring procedure.
Operational metrics
To assess deployment feasibility, I measured inference latency, throughput, VRAM consumption, and retrieval overhead on the hardware configuration described in Table 6. Latency was measured as wall-clock time from prompt submission to final token generation, averaged over 200 randomly sampled MedQA questions. Throughput was measured as questions processed per minute in sequential mode. VRAM was measured at peak allocation during inference using nvidia-smi.
Operational governance and security
AIDx is intended as a clinician-in-the-loop system. In practice, on-premises deployment requires basic governance controls so hospitals can answer three questions for any given output: who used the system, what exactly ran, and what information influenced the answer. The controls below describe the minimum operational safeguards supported by the AIDx design.
-
Audit logging (what happened): record the request timestamp, user/role identifier, patient record identifier (or pseudonym), model version, retrieval index version, and the identifiers of retrieved reference passages. Store response metadata (e.g., token counts, latency) and keep logs within the institutional boundary.
-
Role-based access control (who can do what): restrict actions by role (e.g., clinician: query and view results; administrator: configure deployment settings; auditor: review logs). Require explicit permissions for configuration changes and access to any log data.
-
Versioning and change control (what exactly ran): version the deployed model artifact and retrieval index, and record the active versions on each request. Support rollback to a prior approved version if a regression or incident is detected.
-
Incident response (what to do when things go wrong): define triggers for investigation (e.g., unusual error rates, suspected prompt injection, unauthorized access), assign ownership for triage, and document procedures to disable retrieval, roll back a model/index, or take the system offline.
Ethical and regulatory considerations
All benchmark data used are publicly available. Training data were derived from de-identified MIMIC-IV records. AIDx can be deployed on-premises to support HIPAA-aligned operation. GDPR and the EU AI Act motivate transparency, logging, risk management, and human oversight13,14.
Reproducibility and code availability
To make the evaluation transparent and replicable at the benchmark level, this work specifies: datasets, splits, and dataset revisions (Section 4.4); the exact prompt template (Listing 1); decoding settings (temperature=0, top_p=1, repetition_penalty=1.0); the scoring regex and failure-handling rule; all training hyperparameters (Table 1); and RAG configuration details (Table 2). Per-dataset confidence intervals are reported in Table 3.
To support independent reproduction of the evaluation protocol, Supplementary Algorithm S1 provides pseudocode for the scoring script. The full evaluation code — including the benchmark runner, prompt construction, regex scoring, Wilson confidence interval computation, and the RAG retrieval reference implementation — is deposited at Zenodo (https://doi.org/10.5281/zenodo.19207085). The evaluation can be executed against any OpenAI-compatible API endpoint. The AIDx training code, serving stack, and model artifacts are proprietary and are not publicly released.