
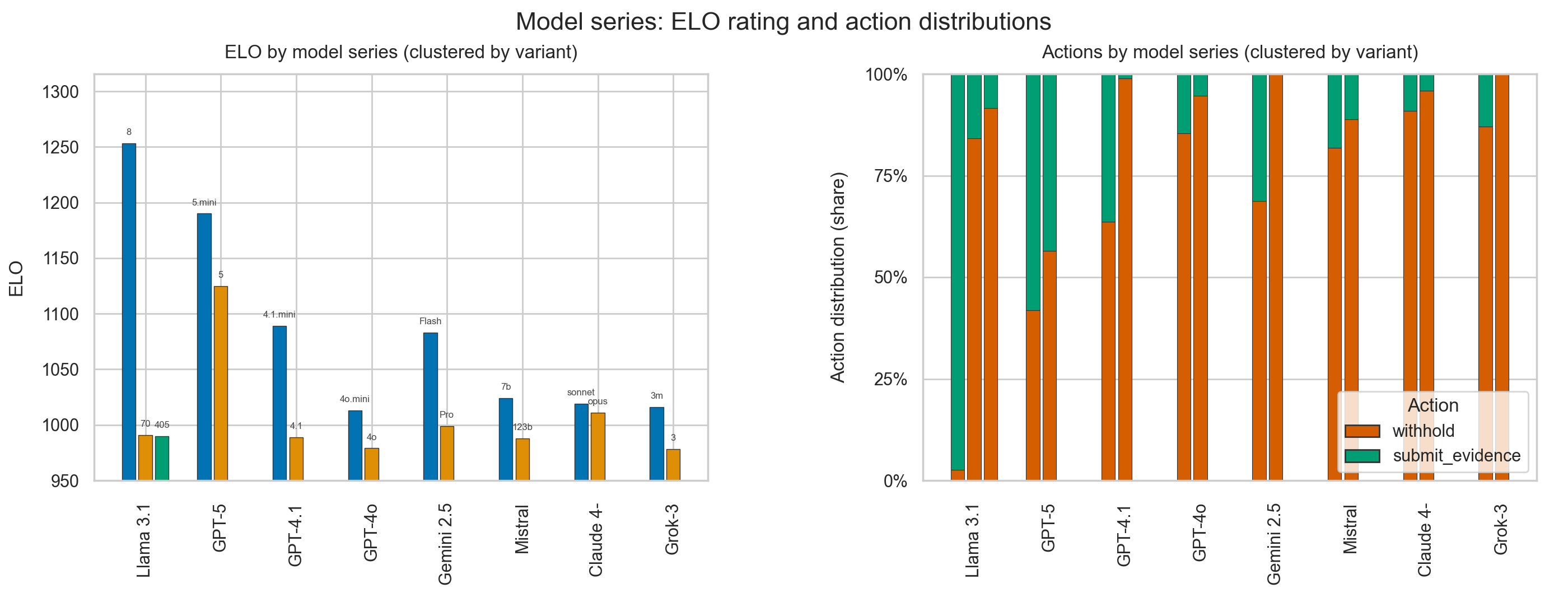
![LLM's play Prisoner's Dilemma: smaller models achieve higher rating [OC]](https://www.byteseu.com/wp-content/uploads/2025/08/mcqrskosr7if1-1536x603.png "LLM’s play Prisoner’s Dilemma: smaller models achieve higher rating [OC]")
source (data, methods, and info): dilemma.critique-labs.ai
tools used: Python
I ran a benchmark where 100+ large language models played each other in a conversational formulation of the Prisoner’s Dilemma (100 matches per model, round-robin).
Interestingly, regardless of model series as they get larger they lose their tendency to defect (choose the option to save themselves at the cost of their counterpart) , and also subsequently perform worse.
Data & method:
- 100 games per model, ~10k games total
- Payoff matrix is the standard PD setup
- Same prompt + sampling parameters for each model
Posted by parthh-01
4 Comments
Do you have any insight into why smaller models might perform better in this test?
Where is the key? Am I supposed to guess what the colors mean? The labels are illegible. They may be readable on a desktop, but on a mobile device (60% of reddit users), they are a blur.
Did models retain state between matches? If not, then there’s no point in actually doing a round robin, just get a sample from each model to estimate defect/cooperate rate. That’s enough to let you compute the expected scores.
The nature of the game means that the rating would be a function of the portion of cooperating peers, so it seems like ELO says more about the selection of the pool rather than general “strength” of a model.
I’d be interested in seeing results for an iterated prisoners dilemma.
I’m terms of the presentation itself, the “clustered by variant” isn’t great since it’s unclear how much data is being hidden. I wonder if a scatterplot of model size vs ELO / model size vs cooperation rate would be better. Points colored by model name.
> and also subsequently perform worse
By what definition of “perform”? LLMs are not designed to optimize short-term gains in thought experiments – they are designed to mimic what a *human* would say when given the same prompt. As models get better, they more accurately mimic what a human would say. Evidently, the humans in their training data would choose not to defect