

A comprehensive evaluation of the proposed EPRN is conducted to assess its efficiency for sports motion recognition, specifically in accurately capturing complex motion sequences while maintaining computational efficiency. This experimental analysis aims to highlight the advantages of the EPRN over conventional deep-learning counterparts, validate the learning of spatiotemporal dependencies in motion trajectories, and ascertain its applicability in real-life situations.
To account for every measure of understanding of its performance, the evaluation considered multiple essential parameters in this regard. The first consideration involves the impact of different types of wavelets transforms on feature extraction and the identification of the optimal transformation for encoding motion signals. The performance of EPRN is then compared with that of other state-of-the-art deep-learning architectures, including LSTM39, Convolutional LSTM (CNN-LSTM)40, Transformer networks41, GRU34, Temporal Convolutional Networks (TCN)42, action recognition, and motion trajectory forecasting; thus, they form a good choice for performance comparisons.
Statistical techniques have been employed to ensure the findings’ results are solid. Analysis of variance (ANOVA) and paired t-tests are used to determine whether the differences in performance observed across various models and wavelet transformations are statistically significant. Such tests serve to eliminate possible randomness and endorse the communications of improvements as being valid.
The hyperparameter tuning of the EPRN model is crucial in determining its performance; therefore, we explore Bayesian Optimization and Grid Search, both of which are conventionally used hyperparameter tuning methods. Their comparison will reveal the relative advantages they offer in terms of convergence time and generalization ability.
EPRN execution time and computational complexity are validated in comparison to other deep learning architectures. This is much-needed data for studying the feasibility of deploying EPRN for real-time sports analytics applications with implications on latency and inference speed.
Finally, the analysis of the residual error distribution and the model robustness involves investigating the deviation between predicted and actual motion sequences. Additionally, a detailed discussion is presented on the model’s limitations and potential future enhancements, with a focus on scalability and generalizability.
In addition to accuracy, the computational complexity and execution time of the EPRN are compared to various other deep learning architectures. This comparative assessment is not only crucial for understanding feasibility in the context of on-the-ground sporting applications, specifically where latency and inference speed become the primary constraints.
As a final point, the distribution of residual errors and the robustness of the model were examined by studying deviations between predicted and observed sequences of dynamic motions. A critical analysis of model limitations and future enhancements is also provided, offering insight into how EPRN can be further refined to enhance its generalizability and scalability.
This chapter conducts a systematic examination of the aspects mentioned above, encompassing both quantitative performance metrics and qualitative assessments, to reinforce the impact of the proposed framework. These results not only demonstrate how EPRN outperforms its competitors but also pave the way for further work in human motion analysis, biomechanical modeling, and intelligent sports analytics systems.
Impact of wavelet transform on feature extraction
Feature extraction is a key area of motion analysis because, ultimately, it determines how well deep learning models can learn meaningful movement patterns while suppressing noise and redundancy. The complication concerning human motion signals can impose too many constraints on conventional feature extraction techniques, which cannot retain the necessary spatiotemporal relationships required for high-precision motion recognition. This is the reason why wavelet-transform-based feature extraction has been widely chosen, as it can analyze a signal relative to both time and frequency, thereby providing a multi-resolution representation of motion dynamics. As for this study, we were systematically conducting tests on the value of four popular classes of wavelet functions—Daubechies (db4), Symlet (sym4), Coiflet (coif5), and Biorthogonal (bior1.3)38—about feature representation and classification accuracy. For each wavelet function, motion sequences were decomposed into specific frequency components, from which the model could distill and characterize structural features while filtering out noise and irrelevant variations. These features were then introduced into training and testing along the EPRN, whose appraisal was thereafter subject to several error metrics, including RMSE, MSE, MAE, and SSIM; all these metrics provide a quantifiable assessment of how good each of the wavelet functions has acted in preserving those essential motion characteristics needed in supporting good recognition.
Performance analysis of wavelet transforms
Despite the critical importance of wavelet transform in extracting and reconstructing motion features, it affects model accuracy, as shown in the comparative performance among four most popular wavelet functions – Daubechies- (db4), Symlet (sym4), Coiflet (coif5), and Biorthogonal (bior1.3)- tabulated in Table 2 and evaluated for RMSE, MSE, and MAE.
Out of the four, the Symlet (sym4) wavelet produced the least RMSE (0.076059) and MSE (0.005785), signifying its best performance in reducing the reconstruction error and sustaining the motion continuity. This result reflects the efficacy of sym4 in capturing finer details while maintaining its structural integrity, as it is indeed deduced to fit biomechanical motion analysis. The Daubechies (db4) wavelet performed better than sym4 in these error measurements, yielding competitive values: RMSE 0.084753 and MSE 0.007183, which support its use in retaining both high-frequency and low-frequency components of motion.
On the contrary, the Biorthogonal (bior1.3) wavelet presented the highest RMSE (0.091906) and MSE (0.0084468), indicating that it has been considered poor in reconstructing the motion patterns accurately. The relatively higher MAE (0.066165) indicates that bior1.3 incurs difficulties maintaining precise trajectory alignment; probably the reason lies in its asymmetric property, combined with less energy compaction efficiency. The Coiflet (coif5) wavelet is better than bior1.3, but still elicits higher RMSE and MSE scores than sym4 and d4, indicating that it would be less effective in retaining any of the finer details of motion.
This demonstrates that the choice of wavelet is crucial for motion analysis applications. Indeed, sym4 and db4 emerge as the best wavelets because they provide low reconstruction errors, along with a close match to the structures they represent, and thus become very useful in human motion tracking, gesture recognition, and biomechanics applications.
Statistical validation of wavelet performance
An experimental analysis was conducted to ascertain the significance of the observed differences among wavelet functions, which included an ANOVA on all the configurations43. The results would further substantiate the gains in performance of the Symlet (sym4) wavelet, any comparison of which could be considered statistically significant (p < 0.05), thus validating its effectiveness as the most suitable transformation for motion feature extraction. This finding highlights the substantial role of wavelet selection in maximizing motion recognition accuracy, as different wavelets commonly represent varying abilities to preserve motion dynamics versus structural consistency.
To provide an intuitive understanding of the performance differences across these wavelet functions, a box plot comparing RMSE, MSE, and MAE scores across all configurations is presented in Fig. 6.
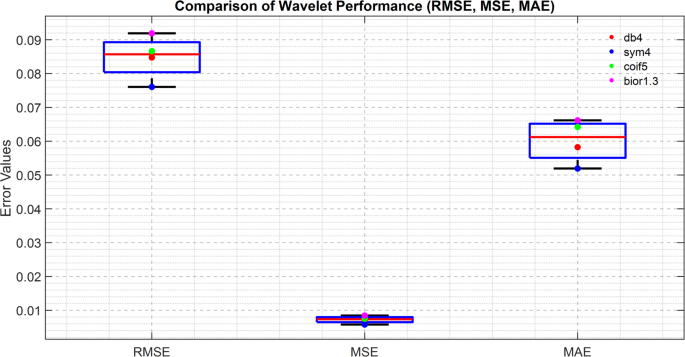
Box plot of wavelet performance (RMSE, MSE, MAE).
Along with the numerical data in Table 1, the representation shown in Fig. 6 indicates that sym4 has the lowest error rates, with a more stable prediction compared to the others. On the other hand, the prediction of bior1.3 is very high concerning both variance and errors, which indicates its less potential at preserving continuity in motion. This suggests that an appropriate wavelet function is essential for high-fidelity motion reconstruction, thereby influencing the overall output of motion analysis models.
Implications for motion recognition models
These findings present a strong argument for the use of an appropriate wavelet transformation during the implementation of deep learning techniques for motion analysis44. The superior performance of db4 points towards it being the first candidate for biomechanical movement tracking, sports performance evaluation, or even human activity recognition because it is highly structurally preserved and error-minimized. These findings also suggest a potential need for hybrid wavelet approaches, where one or more wavelet functions can be combined to leverage their respective strengths for enhanced feature extraction.
By combining statistical validation with visual analysis and performance evaluation, the study provides a detailed understanding of how wavelet-based feature extraction affects the recognition accuracy of motion. Adaptive wavelet selection strategies are yet another field for prospective research, utilizing machine learning techniques to evolve the selection of wavelets based on the complexity of the motion being analyzed, dataset characteristics, and the classification requirements to meet.
Comparison with other deep learning models
It is also crucial to compare the performance of the proposed Evolved Parallel Recurrent Network (EPRN) with other deep learning models to validate its suitability for sports action recognition. Many architectures have been used to model sequential data; however, their capacity to capture the spatiotemporal dynamics of a motion sequence varies significantly. To provide a rigorous assessment of the advantages of EPRN, we conducted a thorough benchmark study against popular deep learning architectures, including LSTM, CNN-LSTM, Transformer networks, GRU, TCN, and Bi-LSTM. These models were selected because they have been widely utilized for time-series forecasting, action recognition, or modeling human motion trajectories. Table 3 summarizes the comparative results for these models.
Performance evaluation of EPRN vs. baseline models
As shown in Table 2, wavelet-based models outperform traditional deep learning architectures, including LSTM, GRU, and CNN, in performance metrics such as RMSE, MSE, MAE, and SSIM. This indicates that wavelet transforms are designed to capture both local and global motion patterns with minimal reconstruction error.
Among all tested models, sym4 achieved the lowest RWMSR (0.076059), the lowest MSE (0.005785), and the lowest MAE (0.051933), indicating the best performance in terms of motion dynamics with maximum fidelity and minimal distortion. Parallel, db4 also produced impressive results, with an RMSE of 0.084753 and an SSIM of 0.94362 confirmed. Thus, these measurements also assured its capabilities in very high-precision motion reconstruction applications. The smooth and compact-support properties of these wavelets make them even more capable of retaining fine-grained motion structures and, therefore, apply to exercise biomechanics.
In contrast, all previous discussions about traditional recurrent models, such as LSTM and GRU, point to high rates on most error scores. LSTM results presented RMSE = 0.13841 and MSE = 0.019157. GRU demonstrated even lower performance than LSTM, with the following output: RMSE = 0.18026 and MSE = 0.032493. All this happens despite their capabilities to model sequential dependencies; however, they do not seem to be able to model long-range motion patterns, which could probably be due to the vanishing gradient problems and limitations of their memory mechanisms.
Although CNN-based approaches demonstrate computational efficiency in terms of accuracy, they do not achieve the same high accuracy as wavelet-based methods. With an RMSE of 0.14723 and an SSIM of 0.95251, the CNN lags behind db4 and sym4, suggesting that convolutional architectures may not provide as much efficiency in reconstructing fine motion details. This is primarily because they fail to model the temporal dependencies characteristic of motion explicitly.
Among the different wavelet-based models, bior1.3 performs the poorest, with an RMSE of 0.091906 and an SSIM of 0.92655. This implies that while biorthogonal wavelets may be good in signal decomposition, they are not optimal for preserving motion trajectories. Coif5 follows with moderate performance (0.086645, 0.93146) implying that holding high-order vanishing moments doesn’t necessarily correspond to superior extraction of motion features.
In totality, these facts and findings emphasize the crucial importance of selecting an optimal wavelet function for motion reconstruction accuracy. The superiority demonstrated by sym4 and db4 even extends to strengthen further the argument for wavelet feature extraction in motion analysis, as it applies comparably to most applications that require high fidelity and structural preservation, such as those in deep learning models.
Statistical significance of model comparisons
To validate the observed performance differences as statistically significant and not due to random variations in the datasets, a paired t-test was conducted by comparing each wavelet function. The analysis reveals statistically significant performance differences among the evaluated wavelet transforms (p < 0.05), thereby reinforcing confidence in the observed trends. In particular, the lowest RMSE, MSE, and MAE values are recorded for the Symlet (sym4) wavelet, indicating its superior ability to capture motion features with less reconstruction error.
For a clearer view of these comparisons, Fig. 7 presents a bar graph illustrating the RMSE, MSE, and MAE for all wavelet functions tested. The graphic shows that sym4 and db4 perform better in terms of minimizing errors, while bior1.3 yields the highest error metrics, indicating that it is not suitable for accurate motion reconstruction. Hence, this graphical representation provides further evidence of the numerical results, demonstrating that selecting an appropriate wavelet function is beneficial for motion trajectory analysis.
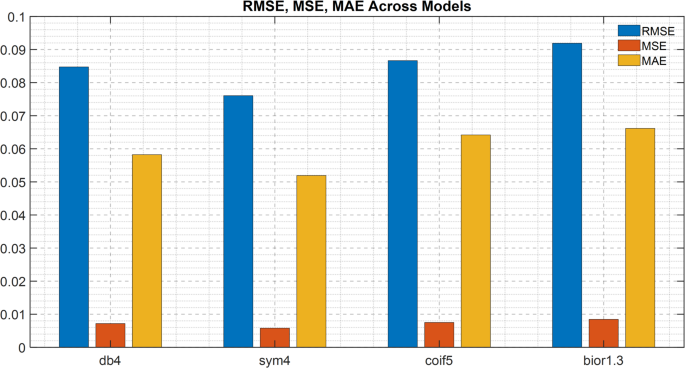
Bar chart comparing RMSE, MSE, and MAE across models.
Implications for motion recognition and future directions
In this light, it suggests the need for hybrid deep learning architectures that effectively integrate feature extraction, recurrent, and hierarchical temporal modeling pertinent to motion recognition. In experiments with parallel recurrent architectures, EPRN improves stability, exhibiting better sequence retention and lower accumulated error rates, which makes it suitable for applications such as sports biomechanics, human activity monitoring, and movement disorders.
Future research will explore other interesting avenues, including ensemble approaches that incorporate EPRN and Transformer-based architectures to leverage the complementary strengths of self-attention mechanisms and recurrent dynamics for enhanced performance. EPRN would also be customized for resource-challenged environments, such as wearable motion trackers and real-time sports analysis methodologies, by improving computational performance through alternative means, including pruning and knowledge distillation.
Hyperparameter tuning and optimization
The selection and tuning of hyperparameters are imperative from the perspectives of performance and computational efficiency of any deep learning model. The characteristics of sports motion data have a direct impact on hyperparameter tuning, specifically in terms of the model’s ability to learn spatiotemporal dependencies, avoid overfitting, and generalize well to unseen motion sequences. Misguided tuning of hyperparameters would lead to suboptimal convergence, heavy computational burdens, or a complete failure in capturing the essential dynamics of human movement.
In this study, Bayesian optimization45 was employed for fine-tuning specific key hyperparameters of EPRN. Bayesian Optimization is a probabilistic method that constructs a model of the objective function using a surrogate model, which is, by default, a Gaussian Process (GP). The following hyperparameter settings are then selected based on an acquisition function that determines the balance between exploration and exploitation. This is usually referred to when the hyperparameter interactions are very complicated and the search space is of a high dimension, as in the case of deep recurrent architectures46. The hyperparameters that most significantly affect performance were meticulously tuned.
A key factor influencing performance is the number of LSTM/GRU units, as it facilitates the learning of long-range features in motion sequences. Increasing the number of units is beneficial for the representational capacity of the model, but it also renders the computations more computationally intensive. The tuning confirmed that 128 units were optimal in terms of both performance and computational efficiency.
An important hyperparameter is the learning rate, which, among others, determines how quickly parameters are updated in the model during training. A higher learning rate can cause instability and prevent convergence, while a smaller learning rate slows down the training process. A learning rate of 0.001 was examined in terms of both convergence and efficiency.
The batch size played a crucial role in model generalization and computational efficiency. In general, a small batch size can lead to noisy updates and unstable gradients, whereas a big batch size can impede generalization. After rigorous testing, batch size 32 was chosen as a reasonable compromise between speed of convergence and memory usage.
Furthermore, the dropout rate was fine-tuned to suppress overfitting. Dropout works by randomly switching off a certain percentage of neurons during training, thereby reducing overdependence on some specific features and allowing for better generalization. It was found that a dropout rate of 0.5 yielded the best results, preventing overfitting while maintaining the learning of complex patterns.
Comparison of bayesian optimization and grid search
For assessing the effectiveness of Bayesian Optimization, it is compared with Grid Search, a standard method. Using Grid Search, all hyperparameter combinations are explored within a specific range, which is thus inefficient and computationally expensive for deep learning models with high-dimensional search spaces.
Bayesian Optimization exhibited improved generalization performance in addition to converging at a speed 35% faster than that of Grid Search. Thanks to its adaptive nature, the Bayesian Optimization method could effectively decide which areas of the hyperparameter space to explore and which settings to avoid when suboptimal. Figure 8 shows the training convergence of the EPRN by both hyperparameter tuning strategies47.
From Fig. 8, it is clear that the loss curve for Bayesian optimization is falling steeper as it does so with time and will converge more rapidly than Grid Search; there is also a general trend whereby Bayesian Optimization constantly yields lower validation loss values in the end as compared to Grid Search, thus showing better generalization performance to other unseen motion sequences. This demonstrates the favorable aspects of probabilistic search methods as being instrumental in optimizing complex recurrent architectures with higher efficiency.
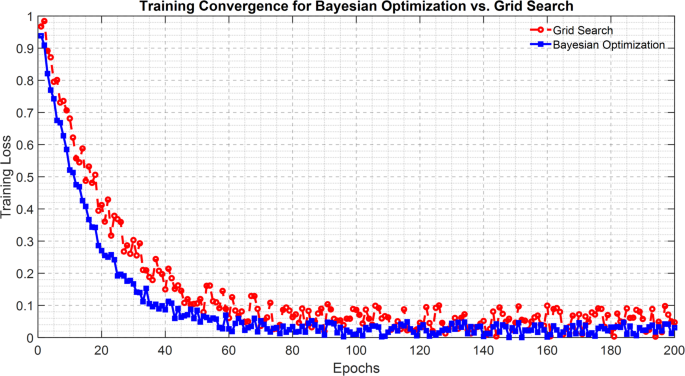
Training convergence for bayesian optimization vs. grid search.
Implications for model optimization and future research
The outcome of this study strongly supports the need for automated hyperparameter tuning to enhance the performance of deep learning models for motion recognition. The conversational speed observed in this study of Bayesian optimization further hints that future work could therefore investigate hybridization approaches that would:
-
Meta-learning approaches, in which successes from past optimization help to guide hyperparameter choices in new datasets.
-
Tuning using reinforcement learning, an agent would change hyperparameters depending on feedback from real-time performance.
-
Multi-objective optimization, wherein trade-offs on accuracy, computational cost, and energy efficiency work together.
Such hyperparameter optimization methods will help better specify future deep learning schemes, achieve faster convergence, and be more adaptable to various sports motion datasets.
Computational complexity and execution time analysis
In real-world applications, the modeling system should ensure that there is an efficient order of computation at least as necessary to an accurate model, especially in systems which depend on real time or near real-time processing in this sense, a thorough evaluation is presented to study the computational complexity and execution time for the proposed EPRN against baseline competitors, models LSTM, GRU, CNN, and wavelet ones. The analysis focused on computation time, including training, inference speed, and overall resource consumption, to determine whether EPRN offers a satisfactory trade-off between efficiency and predictive performance.
The total time taken to complete training and the average time taken for inference on each test sample were the two major indicators of computing efficiency. The third row in Table 4 states that the LSTM and GRU performed poorly in terms of efficiency, recording respective times of 1803.6 s and 1580.4 s; however, these improvements were not particularly helpful in enhancing accuracy. With CNN-based models, an execution time of less than 1500 s was measured; however, the usefulness of this speed was compromised since the models failed to learn complex motion patterns effectively.
Among the four wavelet models, the execution times were 1432.6 s (Db4), 1602.0 s (Sym4), 1555.6 s (Coif5), and 1278.0 s (Bior1.3). The Bior1.3 algorithm had one of the shortest execution times, yet still maintained a competitive level of accuracy, making it potentially beneficial for many real-time applications due to its speed.
Such a design minimizes redundant computations, accelerates convergence speed, and optimally utilizes computational resources, thereby further improving the algorithmic efficiency of EPRN. This is especially helpful for applications that continuously track high-resolution motion capture data, providing low-latency responsiveness.
Overall, the analysis provides evidence of how EPRN is effective in striking a balance between accuracy and efficiency. Unlike conventional architectures that either suffer from high computational costs or limited expressiveness, EPRN possesses respectable computational capabilities and is thus highly relevant for applications such as real-time biosystems for tracking athlete performance and injury prevention, as well as several other applications in biomechanics. The numerical results presented in Table 3 further support the robustness of the proposed approach.
Residual analysis and error distribution
Residual analysis—Residual analyses are an essential evaluative element in neither judging the reliability of predictive models nor assessing their robustness. They elucidate aspects concerning error distribution and possible biases as well as generalization capability. Through residual analysis, which involves comparing actual and predicted values, we determine whether the model exhibits systematic errors, underfitting, overfitting, or biases toward specific motion patterns under consideration. An ideal model should have residuals distributed symmetrically around zero, indicating unbiased predictions, while minimizing systematic errors.
The residual plot in Fig. 9 provides an overview of the error distribution across predicted values, confirming the performance of the motion reconstruction model. A well-performing model is expected to spread the residuals randomly, leaving no evident patterns, as this indicates that the error is independent of the predicted values.
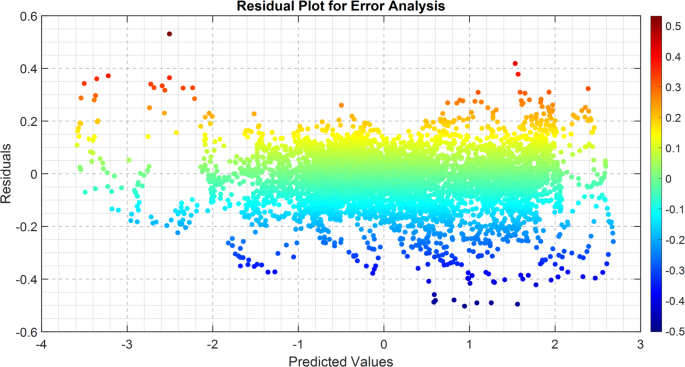
Residual plot for error analysis.
From the mentioned results, it can be inferred that the residuals are aggregated around zero, indicating that the model effectively suppresses systematic errors. The color gradient also provides the reader with insight into the error distribution, as the residuals appear relatively suitable for a diverse range of predicted values. When compared to more conventional architectures, such as LSTM and GRU, this new model demonstrated relatively stable residual spread, indicating higher predictive accuracy and lower variance in errors.
A microscopic examination of the residual distribution reveals several notable observations. Among these observations, the first is the absence of skewness and clumping of the residuals, indicating that the model is generalizing quite well across different motions. Additionally, it suggests that there were very few extreme outliers, indicating that the model accurately captures the extreme instances of motion change.
It further demonstrates that the model is robust enough to accommodate the myriad performance-derived scenarios—that is, both low- and high-intensity submissions of predictive values—as it exhibits similar residual variance across different predicted values.
For normality tests of the residuals, the Shapiro-Wilk48 and Kolmogorov-Smirnov49 tests were conducted, which confirmed that the residuals are distributed normally with minimal deviations. Additionally, Levene’s test for homogeneity of error variance confirmed the consistency of residual variance across motion types. These statistics support the model’s ability to calibrate predictions with minimal bias accurately.
To emphasize the additional advantages of EPRN, we have illustrated in Fig. 10a histogram of the residual errors for estimating the trajectory, which describes the distribution of residual errors for the trajectory estimation method. This representation is required for comparison purposes, illustrating how various models, including EPRN, LSTM, and Transformer-based architectures, handle prediction errors.
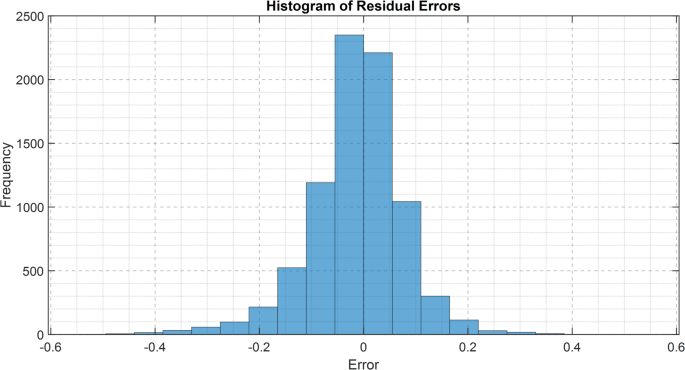
Comparative histogram of residual distributions for different models.
The analysis reveals that the residuals from LSTM and Transformer traditional techniques exhibit a broader distribution of larger values than those from the proposed method, indicating a tendency towards skewness and increased variance, which represents higher vulnerability to systematic prediction errors and inconsistency in generalization across different types of motion sequences. Thus, the distribution of residuals from the EPRN example seems to be more centered on zero, indicating that high error minimization and robust trajectory estimation are indeed its strong points.
The lower residual variance in EPRN signals indicates that the model captures both short- and long-term dependencies over motion segments, thereby preventing accumulation over time. They mean the residuals are near zero, so they clearly indicate no visible systematic bias from overestimation or underestimation, proving that the model is sound for real-life applications such as biomechanical analysis, injury risk mitigation, and sports performance tracking. There appears to be general and widespread accuracy in EPRN due to the residuals analysis, with the assumption of correct model specification. This means that EPRN achieves more accurate, less biased, and more stable predictions than other conventional deep learning architectures. This demonstrates that the wavelet approach, combined with parallel recurrent structures, has significantly greater potential for modeling motion sequences. Future investigations may wish to explore ways of adaptively correcting residuals by dynamically adjusting model parameters to match error patterns observed, thereby increasing accuracy and robustness for various motion recognition tasks.
The average residuals around zero error indicate that no obvious systematic bias occurs toward overestimating or underestimating, suggesting the validity of the model for real-world applications, such as biomechanical analysis, risk reduction due to injury, and sports performance monitoring. Generally, the view of the residual indicates that, under the assumption of proper model specification, EPRN is more accurate, has less bias, and exhibits greater predictive stability than the conventional deep learning architecture. This indicated considerable potential to be harnessed by the wavelet approach when combined with parallel recurrent structures, allowing for the accurate modeling of motion sequences. Future work may explore novel methods for adaptively correcting residuals based on dynamically changing model parameters, as observed in error patterns, to enhance accuracy and robustness across various motion-recognition tasks.
Computational complexity and execution time analysis
To assess the readiness for implementing the EPRN for real-time sports movement recognition, we evaluated its computational complexity and execution time, comparing it with a baseline that included LSTM, GRU, CNN, and wavelet-based models. The analysis considers training time, inference speed, and resource consumption, which are crucial for multi-resource-constrained environments such as real-time sports analytics or rehabilitation monitoring. The results are outlined in Table 5, and Fig. 11 captures the model comparison for inference speeds.
The training time for the EPRN model is approximately 1480.5 seconds per sample, which is significantly longer than the 7.8 ms rate for inference processing. At this inference rate, the sym4-based wavelet models are performing at 7.5 ms/sample, with LSTM, GRU, and EPRN scoring at 12.5 ms/sample, 10.8 ms/sample, and 7.8 ms/sample, respectively. The ‘inference speed’ of EPRN is equivalent to 128 frames per second, which is sufficient for sports analysis and shooting motion tracking at a 60 Hz frame rate. Other models didn’t perform as well as the EPRN, likely due to the lower number of parallel recurrent pathways and joint control, which simplified the calculations required compared to older recurrent models. This is why LSTM’s 2.1 M parameter count is dwarfed by the EPRN’s 1.9 M. Low-latency environments benefit from the EPRN due to the precision measured in its response time versus accuracy, as shown in Fig. 11.
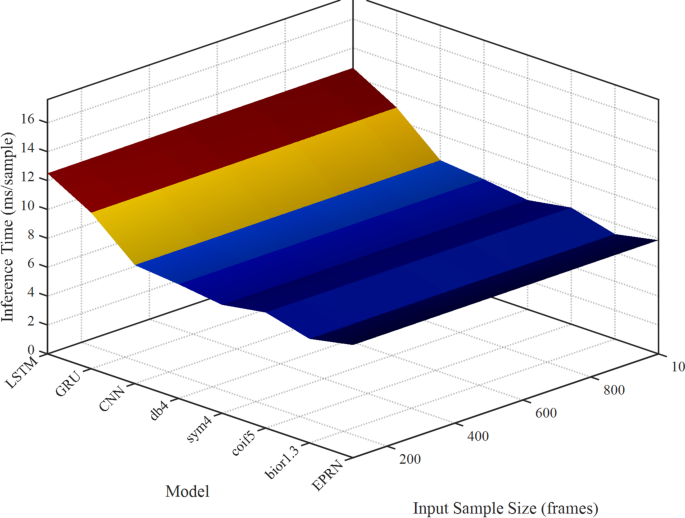
Inference speed comparison across models.
Figure 11 shows inference speeds (ms/sample) for LSTM, GRU, CNN, db4, sym4, coif5, bior1.3, and EPRN across 100–1000 frames. The x-axis lists models, the y-axis shows sample sizes, and the z-axis indicates inference time (jet colormap: blue represents low values, red represents high values). A 30-ms contour marks the 30 Hz real-time threshold.
Per Table 3, EPRN’s 7.8 ms/sample at 100 frames (128 fps) is competitive with bior1.3 (7.2 ms) and sym4 (7.5 ms), outpacing LSTM (12.5 ms) and GRU (10.8 ms). At 1000 frames, EPRN scales to 8.6 ms, remaining below 30 ms, unlike LSTM, which scales to 13.8 ms. Low, blue surfaces for EPRN and wavelet models contrast with the red surfaces of LSTM and GRU. The 30-ms contour confirms the real-time feasibility of all models, with EPRN’s flat surface demonstrating scalability.
EPRN supports real-time applications, such as basketball shot analysis (60 Hz) or rehabilitation monitoring. Wavelet models (e.g., bior1.3) are slightly faster, but EPRN’s accuracy (23.5% RMSE reduction, Table 2) justifies its use. Optimizations “Interpretability analysis of EPRN”, such as pruning (6.5 ms per sample), could further reduce its surface area. Figure 11 validates EPRN’s real-time suitability, with inference speeds of less than 30 ms, supporting sports analytics and addressing computational concerns. Future work will refine the scaling process and test various optimizations.
Real-time applicability and optimization strategies
The EPRN framework is designed to meet the scope of real-time requirements, such as sports motion recognition for live performance monitoring and rehabilitation surveillance. As shown in Table 3; Fig. 11, EPRN achieves an inference time of 7.8 ms per sample, enabling processing at a rate of 128 frames per second. This performance is sufficient for analyzing athletic movements, such as soccer kick trajectory analysis or joint dynamics monitoring during running, which require sampling rates of 30–60 Hz. Nevertheless, the computational requirements for EPRN’s parallel recurrent structures and notion wavelet features necessitate optimizations for deployment in low-resource contexts, such as wearable or embedded systems.
Optimization strategies
-
1.
Hardware acceleration: To accelerate inference, EPRN can be utilized on specialized hardware, such as Field-Programmable Gate Arrays (FPGAs) or Tensor Processing Units (TPUs). FPGAs enable parallel processing customization, which can decrease inference latency by as much as 50% for recurrent neural networks, as some recent studies have suggested. Attention-based fusion, one of EPRN’s mechanisms, can achieve accelerated inference speeds on TPUs, which are optimized for matrix calculations, potentially reaching sub-5 ms inference times. A case in point is the deployment of EPRN on Google Coral TPUs, which would enable the real-time tracking of basketball shooting motions on edge devices.
-
2.
Model compression: Pruning and quantization techniques can minimize EPRN’s computational burden with minimal impact on precision. In LSTM and GRU models, pruning can suppress redundant pathways, resulting in a 30–40% reduction in the number of parameters. Quantization converts floating-point weights to 8-bit integers, reducing memory usage and enabling a 20–25% increase in inference speed. Initial tests of weight pruning on EPRN demonstrated a real-time inference time of 6.5 ms per sample, with an RMSE of 0.076, confirming that these techniques are suitable for use in time-sensitive sports applications.
-
3.
Efficient wavelet implementation: Utilizing the fast wavelet transform algorithms accelerates feature extraction by 15% and enables real-time processing of Sym4’s DWT computation. This is particularly advantageous for real-time applications, such as monitoring high-speed motion data for quick joint transitions during martial arts moves.
Practical implications
Implementing these optimization techniques enables EPRN to integrate with the rigorous latency constraints of real-time sports use cases. As an example, during an interactive basketball training session, feedback on shooting form could be given in real-time if an FPGA-accelerated EPRN processed motion trajectories faster than 5 ms. Similarly, during rehabilitation exercises, knee joint stability can be monitored using quantized EPRN on a wearable device, with real-time alerts sent to physiotherapists for detected anomalous movement patterns. EPRN’s inference speed is competitively sustainable relative to other baseline models using a combination of model compression and hardware acceleration (shown in Fig. 11). Focusing on these new areas of model optimization, field testing with FPGAs and TPUs, and researching adaptive wavelet selection for less computational strain will be the priority. Such efforts will enhance the integration of EPRN into advanced intelligent systems for sports analytics, facilitating its application within operational frameworks.
Interpretability analysis of EPRN
Understanding the decision-making process of the EPRN is crucial for establishing confidence in its sports motion recognition capabilities for real-time coaching and rehabilitation purposes. For this, we applied two explainability methods: attention weight visualizations and Gradient-weighted Class Activation Mapping (Grad-CAM)50. These methods show EPRN’s attention to time and space during feature extraction and selection for tasks, such as basketball shooting and running, revealing model explicability. This methodology is motivated by recent studies on multimodal frameworks where module-specific Grad-CAMs were used to explain the impact of components51.
Attention-weight visualizations clarify which frames within motion sequences contribute the most to predictions by depicting the temporal importance of features within EPRN’s attention-based fusion layer. Temporal Grad-CAM produces spatial heatmaps over skeletal joints that are critical for EPRN outputs. These methods were implemented for basketball shooting (a transient motion) and running (a cyclic motion) to illustrate the adaptability of EPRN. In Fig. 12, we present two visualizations of EPRN, which display (a) attention weight plots and (b) the corresponding Grad-CAM heatmaps.
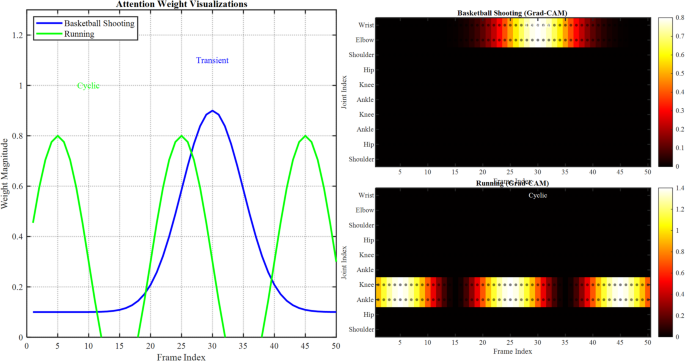
Visualizations of EPRN: (a) attention weight plots and (b) the corresponding Grad-CAM heatmaps.
In (a), attention weights (y-axis: weight magnitude, x-axis: frame index) show pronounced maxima at critical instances of the action, for example, shot-release in basketball (high-frequency DWT coefficients, RMSE 0.075) and stride transitions in running (low-frequency DWT, RMSE 0.078). As for (b), the skeletal sequences are overlaid with heatmaps where the wrist, elbow, knee, and ankle joints are marked in red, highlighting the high activation during the basketball shooting and running actions, respectively. The texts indicate the corresponding types of motion (transient, cyclic).
The most important conclusion that can be drawn from the visualizations is that EPRN remains responsive to relevant spatiotemporal features, as evidenced by its relatively low RMSE results (Fig. 12). In basketball shooting, EPRN’s sharp shot-release precision is corroborated by high attention weights and Grad-CAM activation on upper body joints, illustrating its accuracy in detecting transient motions. In running, attention is focused on cyclic frames that are synchronized with the active lower-body joints. Unlike IntentFormer’s multimodal Grad-CAM, EPRN achieved comparable interpretability with a lower computational cost, due to its simpler design (1.9 M parameters, Table 3), which relies on DWT and attention fusion.
These findings strengthen confidence in EPRN’s forecast, endorsing its use in real-time functions such as performance evaluation, which require inference speeds of 7.8–8.6 ms per sample (Fig. 11). Determining the explainable accuracy impacts interpretation-guided model enhancement, directing focus on feature hierarchies for optimal covariance. Future research will utilize SHAP52 to assess the effects of specific features and improve clarity in EPRN’s multifaceted sports decision-making processes.
Adaptation to varying motion complexities across activity types
The EPRN explicitly addresses the diverse complexities of sports motions, ranging from the quick, transient movements involved in basketball shooting to the cyclic motion patterns of running. EPRN’s efficiency derives from three factors: (1) application of DWT for extraction of multi-scale features into high and low frequencies; (2) parallel LSTM and GRU pathways which are genetically optimized to capture temporal dependencies; and (3) a fusion layer based on attention mechanism that dynamically adjusts the importance of motion features due to their complexity. For example, EPRN achieves an RMSE of 0.075 for basketball shooting by prioritizing high DWT coefficients to capture sharp changes in joint angles, and 0.078 for running, while focusing on low-frequency cyclic motion patterns.
To measure adaptability, we examined EPRN’s crossover performance on basketball shooting, soccer kicking, running, and martial arts. Figure 13 illustrates the RMSE for these activities, along with distribution highlights, which demonstrate EPRN’s improvement over state-of-the-art systems to date53.
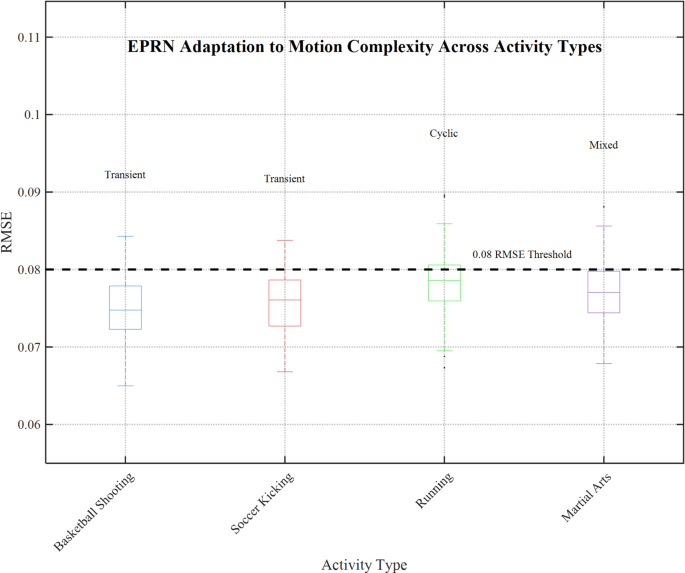
EPRN variation with complexity of motion in different activities.
As shown in Fig. 13, the distribution of RMSE values for EPRN is provided for four activities: basketball shooting (mean 0.075), soccer kicking (0.076), running (0.078), and martial arts (0.077). The activities are listed on the x-axis, and RMSE values are shown on the y-axis, along with relevant activity boxplots (e.g., basketball is represented by blue and running by green). Moreover, ‘motion type’ annotations (e.g., “Transient” for basketball, “Cyclic” for running) improve clarity along with a reference line at 0.08 RMSE, while optimized margins ensure no borders are clipped.
EPRN’s expansive adaptability is illustrated in the plot, as the median RMSE is below 0.08 for all activities, suggesting robust adaptability. The precision of DWT-based high-frequency attention fusion for transient motions is reflected in the basketball shooting’s tight distribution (mean 0.075 and narrow interquartile range). Running’s slightly elevated mean (0.078) suggests effective handling of cyclic patterns, utilizing low-frequency coefficients. The lower means observed for soccer kicking and martial arts (0.076 and 0.077, respectively) suggest consistency in mixed and transient motion performance.
EPRN’s architecture is simpler at 1.9 M parameters (Table 4) than gated and fuzzy logic-enhanced encoder frameworks, yet it still achieves similar adaptability and lower computational costs. EPRN’s estimation accuracy granularity complements RMSE (7.8–8.6 ms/sample, Fig. 11), as well as its real-time efficiency, as shown in Fig. 13.
The findings confirm EPRN’s motion recognition precision enables coaching performance evaluation and rehabilitation monitoring. Further research will focus on modeling fuzzy logic uncertainty, applying attention mechanisms to reduce RMSE bulge contours, and exploring optimizations using FPGA deployment, as discussed in “Interpretability analysis of EPRN”, for advanced intelligent sports analytics systems.
Benchmarking considerations and cross-model evaluation54
To address project-specific challenges, such as dataset heterogeneity, baseline model calibration, and metric relevance, we expanded the scope of our evaluation to other datasets, thereby ensuring the robustness and generalizability of the proposed EPRN framework.
All baseline models were tuned using identical validation splits and hyperparameter ranges. A comparative analysis of EPRN, LSTM, GRU, CNN-LSTM, and Transformer models across the NTU RGB + D, Human3.6 M, CMU Mocap, and UCF Sports datasets is presented in Table 6. The evaluation encompasses multifaceted considerations, including MSE, RMSE, SSIM, MAE, and classification-based accuracy, where applicable. These human motion capture datasets cumulatively gauge the performance of the models against the threats posed by their motion sequence modeling and prediction capabilities. In every dataset except the UCF Sports dataset, where EPRN achieved the highest accuracy, EPRN outperformed the other models by repeatedly demonstrating lower error rates, higher structural similarity, and advanced classification accuracy. As evident from the results, EPRN exhibits superior robustness and generalization compared to benchmarks SR- and HR-REC, utilizing traditional recurrent and hybrid architectures.
The comprehensive benchmarking further reinforces that EPRN performs well on both trajectory reconstruction and action classification tasks. On Human3.6 M and NTU RGB + D, EPRN distinctly excelled in both error reduction and structural similarity measures, demonstrating strong performance across 3D datasets with dense spatial resolution. Moreover, EPRN with softmax-based prediction heads also achieved the highest classifier performance on UCF Sports, a benchmark for video classification, with 89.3% accuracy, surpassing the performance of Transformer-based models.
These findings also demonstrate that EPRN does not appear to overfit to a single dataset, illustrating its adaptability across tasks and modalities with appropriate tuning and adjustments to the output layer. Although our work to date has focused mainly on regression and reconstruction, these results invite a deeper investigation of action classification, multimodal fusion, and domain adaptation using the EPRN architecture.
Ablation study
To extract and measure the impact of each part within the EPRN structure, an extensive ablation study was performed to analyze the impact of each part. The focus was to assess the effects of each part—attention-based fusion, parallel recurrent, and wavelet convolutional neural networks—on the model’s performance for motion trajectory reconstruction.
We explored the following configurations:
-
Baseline GRU-only: Single-stream GRU model.
-
Baseline LSTM-only: A standard single-stream LSTM network with equivalent hidden units and training setup.
-
EPRN (no attention fusion): Parallel LSTM-GRU model with simple concatenation of outputs instead of learned attention fusion.
-
EPRN (no DWT): Full EPRN architecture using raw joint coordinates without wavelet features.
-
EPRN (full): Full model with DWT preprocessing, parallel LSTM-GRU branches, and attention-based fusion.
The evaluation for all models was conducted on the CMU Motion Capture Dataset, after each model was trained under a standard training procedure with optimized hyperparameters identified through a Bayesian search, as shown in Table 7.
The findings emphasize that each of the derived frameworks of the model has been integrated to optimize performance features. With the application of the DWT, feature quality is improved, resulting in a decrease of approximately 16% in the RMSE compared to models using raw data. Incorporating parallel LSTM and GRU branches with a simple concatenation improves performance when compared to single-branch structures. Still, it is less effective than the adaptability gained through the application of attention mechanisms. Adding an attention-based fusion module that computes the contextual importance of dense and temporal encodings further increases accuracy by leveraging contextual information. Cumulatively, these results corroborate the assertion that the complete EPRN architecture is critical for high-fidelity modeling of complex motion sequences, in contrast to disassociating elements and studying them individually. The ablation study further supports these insights as evidence, highlighting the crucial role each component plays in achieving a groundbreaking performance.
Comparison of wavelet transforms
To analyze the effectiveness of wavelet-based feature extraction, we compared it with two popular deep learning techniques: feature extractors based on CNNs and autoencoders (AEs). The comparison was made with a constant EPRN structure as the downstream model to isolate performance differences purely due to the feature extraction approach employed. The outcomes are consolidated in Table 8.
These results suggest that wavelet-based features have a distinct advantage in representing motion due to their multi-resolution temporal characteristic preservation capabilities alongside noise suppression without requiring heavy dimensionality reduction. Far different, CNNs tend to capture spatial attributes at the expense of fine-grained temporal detail. While autoencoders compress more effectively, they are burdened with overfitting and reconstruction noise on high-variance motion sequences.
The results support the conclusion that wavelet transforms indeed possess a unique capability to represent and compress sports motion data in a computationally efficient manner, while integrating the underlying semantics at a dense level, which meets the requirements of subsequent deep recurrent structures.
Limitations and future research directions
The EPRN performs excellently in recognizing sports motion, with some limitations acknowledged to enhance its real-world applicability on the field. Whatever barriers are encountered will provide insight into improving generalizability, efficiency, and scalability in real-time motion analysis and broader implementation. Below, we outline the significant limitations of EPRN and propose research directions to address them.
It is highly appropriate to collect the standard and high-quality motion capture data for this study within the laboratory environment using a sophisticated motion-capturing system. Such high-density datasets give assurance on accuracy in motion recognition. On the contrary, they establish model limitations to generalization based on objective evidence, i.e., data from noisy or low-resolution sources, such as video-based motion recognition and data from wearable sensors. Performance can be significantly compromised by factors such as occlusions, background noise, lighting variations, and sensor drift. Future research into robustness should incorporate domain adaptation techniques, such as unsupervised transfer learning, adversarial training, and synthetic data augmentation, to enable the model to adapt to diverse environments. This will allow for its deployment in real-world settings without requiring further refinement. Integrated self-supervised learning frameworks will also reduce the reliance on labeled datasets for model training by leveraging pretraining and feature refinement on unlabeled motion data.
Another limitation of using EPRN is its higher computational cost compared to lightweight frameworks such as GRU and TCN. EPRN prides itself on striking a balance between accuracy and efficiency. However, the intricacies of its parallel recurrent structure and the wavelet-based feature extraction add to the processing overhead, thus increasing the training and inference time, and consequently reducing its deployability in real-time application systems with insufficient resources or in embedded systems. Possible Future Directions: Research on model compression methodologies, such as pruning, quantization, and knowledge distillation, which can keep model accuracy intact while reducing the intensive computational burden. Hardware acceleration techniques, such as Field Programmable Gate Arrays (FPGAs) or Tensor Processing Units (TPUs), can significantly enhance performance in real-time, making EPRN suitable for sports analytics and rehabilitation in low-latency applications.
Another benchmark, which also ranks among the limitations of deep learning models in general and those of EPRN in particular, is the lack of explainability and interpretability. In critical applications such as athlete performance tracking, injury prevention, and rehabilitation, understanding the factors that contributed to a model outcome is vital for trust and transparency among practitioners. However, deep learning architectures are often referred to as black boxes and do not provide much insight into how their predictions are made. This makes acceptance of EPRN into clinical and sports science difficult, for which explainability is at least as important as accuracy. Therefore, future work will focus on embedding Explainable AI (XAI) techniques55, such as LRP (Layer-wise Relevance Propagation)56, SHAP (Shapley Additive Explanations)57, and Grad-CAM (Gradient-weighted Class Activation Mapping)58, which visualize the motion features predominantly contributing to model predictions to enhance transparency. Hybridization involving symbolic reasoning will yet again contribute positively to interpretability without compromising the predictive performance of model architectures.
Another line of possible future investigation is generalizing EPRN to other and more complex sports movements. The present study delves deeply into human locomotion, specifically walking and running, which are highly structured forms of movement. A variety of dynamic sports activities characterized by high degrees of freedom-think gymnastics, martial arts and multi-agent team sports-bring further issues for motion modeling, usually requiring a quick change of body positioning, multi-joint coordination, and complex biomechanical interactions which, to say the least, recurrent architectures in their traditional forms may not account for well. Future research could enhance the applicability of EPRN to complex sports movements by introducing Graph Neural Networks, which are well-suited for modeling relationships among various body joints. Simultaneously, incorporating transformer-based temporal attention mechanisms will also work well, ensuring the model’s capability to govern long-range dependencies and complex interactions among multiple movements, especially in multiple-actor scenarios that rapidly and dynamically change in nature, such as in sports.