
![[OC] Vocabulary size at each English proficiency level](https://www.byteseu.com/wp-content/uploads/2025/12/fiye0lm4v86g1-1024x691.png "[OC] Vocabulary size at each English proficiency level")
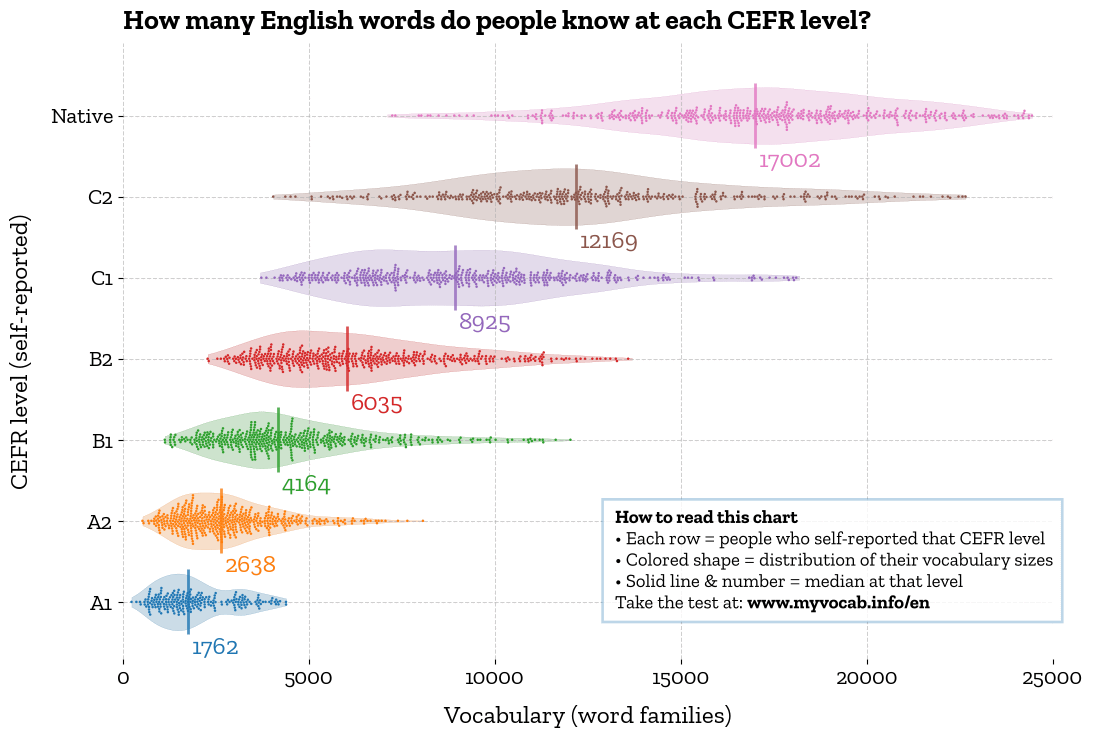
The data comes from a test I built that measures receptive vocabulary — the number of words a person recognizes (but may not necessarily use). It places everyone — from a student who has just started learning English to an educated native speaker — on the same scale. The units are word families (so limit, limited, and limitless count as a single unit). Users self-reported their CEFR levels.
It’s striking to see how much one has to learn to progress from level to level and potentially reach the native range.
Posted by RevolutionaryLove134
34 Comments
Cool test! Took 2 mins and I learnt some things!
I feel like part of the spread has to do with the original language of the user.
Someone who natively speaks a Germanic or Latin language is going to probably know quite a lot of Germanic and Latin words, respectively. Although their overall grasp of the language might not be great. Conversely someone from an unrelated language might need to have studied for a long time to match the vocab depth, but would have a much better grasp of other areas.
Took the test. It was really interesting. A few times it made me question my sanity because of the fake words.
It correctly identified me as a native speaker.
Phew, I have native level English!
Nice test – will it be available in other languages?
Cool test and data! One observation: the output word count from the test is unreadable when on dark mode (Android, Firefox). The dark blue text is almost the same as the dark grey background
Re: Your test. Yes, I do know the meaning of the word enceinte. It just doesn’t happen to be English. :p
Excellent little app you have there. Good job!
Can you fix the German test? It always freezes on the last word and I desperately need to know how bad I am at German.
Also thank you, lots of fun!
what if they have a native vocabulary but heavy accent or makes grammar mistakes?
It is not size that matters but how do you use it
I’m glad I scored above the median (?) native speaker, because I’m pretty sure I’d do a lot worse in my native language
The German test gets stuck on the last word.
https://preview.redd.it/5jehow00396g1.png?width=720&format=png&auto=webp&s=4c7ea0529b69d3186bdd745a271da090579ff4fc
Very nice. I’m a non-native speaker, but I started with English in school 20 years ago. Perhaps the only subject I ever needed IRL, to be honest.
You should do this test but for risk literacy
The test is really well made. I’m C1 it seems. There are so many words that I’ve read and heard countless times, but don’t know the exact meaning of. For example, I will typically understand a sentence with words like “embellish” or “egregious” in it without really knowing the word, and so I don’t bother looking it up. Maybe I should bother.
Nice work, and very cool test!
~~Someone already mentioned that for some languages, the last word (if the result is non-trivial, as in if you didn’t press all “don’t know”) freezes up and doesn’t show the results. Can confirm the bug for Russian as well~~
https://preview.redd.it/uacjw1ce596g1.png?width=715&format=png&auto=webp&s=572a9d9ad4423f45f30df3fdbf4cb0a7ce7817e0
Seems like you’ve already fixed the bug, good job!!
Interesting. I am honestly surprised that the distribution curve isn’t larger for native speakers. Perhaps that means it isn’t so hard to raise someone’s reading level. I am at 90th percentile despite only knowing 23.5% more words than the average person.
This is pretty cool. Thanks!
im a native speaker and i got C1
amazing
God damn these stupid violin plots!
What exactly is the Y axis units between B1 & B2? What’s difference between green points above B1 and below that line.
A histogram if modality is important, a box and whiskers if it’s not.
Yeah yeah, those won’t look ‘as detailed’… But that’s just it you’re not adding detail to data, you’re adding noise to art.
/Rant
Avoided the fake words and got the definitions correct…. A few of those fake words as others have said had me questioning myself and other words …. I may start using them see if I can get one or two going in a friend group
Cool stuff!! What did you use for the dataviz if I may ask?
What is the difference between C2 and Native?
Great test, I do feel like some of the options when it asks you to define a word are a bit weird, but it might be just due to alternative meanings or me being dumb.
Very interesting! It aligns reasonably well with what I’ve read before on the vocabulary size per CEFR level, although a bit smoother of a curve (also, A1 seems quite a bit higher than expected). If you’re curious, you can find a non-paywall link to the paper that their definition of a word family is based on here: [https://www.lextutor.ca/morpho/fam_affix/bauer_nation_1993.pdf](https://www.lextutor.ca/morpho/fam_affix/bauer_nation_1993.pdf) .
An interesting thought is that the productive vocabulary growth in real terms is probably a good deal larger than this suggests; as you progress in a language, you not only recognize more word families, but you’re able to use more members of the word families you already know. For instance, the Paul Nation article there gives 16 different words within the single word family “develop”. Eyeballing it, an A1 speaker might only be able to productively use maybe 3-4 of them, whereas a native speaker would be able to use all or nearly all. So while the above may show that a native speaker knows “about 10 times as many words” as an A1 speaker, I wouldn’t be surprised if the active vocabulary of a native speaker were 20 or 30 times larger.
Best A2 is stronger than worse C2? hehe. Great system that is.
Thanks for the fun test! One note, in dark mode the final result is almost unreadable because it’s dark blue against a black background. And that’s what I’ll blame for my score being lower than I’d like!
I took the test in German and English.
The German one is a little wacky because it didn’t use the capitalization rules
I…. C2. Believe you not?
I’m classed in C2 category. I’m a native English speaker, but I don’t know the meaning of many words (just know they exist), so I’m not entirely surprised
Really well done
Thought I was hot stuff but nope, 48% vs Native speakers (classified C2, 15300)
That said, I was very honest (and found all 10 fake words) so I suspect some people are being a bit generous. I suspect the median person isn’t taking this test either 🙂
https://preview.redd.it/bis74smqi96g1.jpeg?width=583&format=pjpg&auto=webp&s=29f3c1aca40ceae5f737044fc86b3ee0c0de099a
I’m Italian, I studied Latin and German and IMO this test is broken from someone like me since most of the hard words are either Germanic or from Latin\French.
Nice data and fun test. One remark regarding the test – at least for Polish it gave weird options as answers, like for “intruz” / intruder, I’m guessing the answer was “gość” / guest probably because intruder is an unwanted guest, but that’s a really bad way to put it if it’s missing the adjective.
Would be interested in seeing this for Japanese