


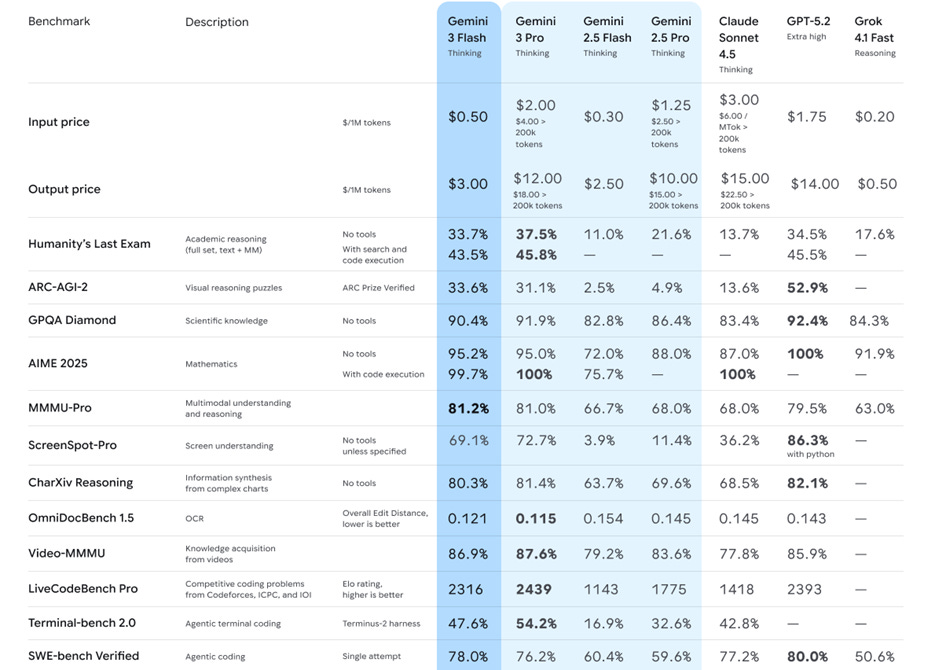
It was a big week of releases, as AI providers put out their best models and updates before the end of year. The biggest release of the week was Google launching Gemini 3 Flash AI model, with integrated multimodal understanding of text, image, audio, and video and offering advanced reasoning capabilities with lower latency and cost.
Google boasts Gemini 3 Flash has “frontier intelligence built for speed” and performance metrics back it up. Gemini 3 Flash benchmark performance is stellar: 78.0% on SWE-bench Verified, 95.2% on AIME 2025, 33.7% on HLE. This beats Gemini 2.5 Pro and Claude Sonnet 4.5 overall and comes close to Gemini 3 Pro, even beating the latter on SWE-Bench Verified.
Gemini 3 Flash is trained for broad usage across real-time workflows and agentic applications, and Google is deploying it widely, using it as the new default in the Gemini app, AI Mode in Google Search, and Google’s developer tools such as Gemini API, Android Studio, and Vertex AI. The API cost for Gemini 3 Flash is $0.50/M input tokens and $3.00/M output tokens, higher than Gemini 2.5 Flash but significantly less than competing similar-performing AI models. This makes Gemini 3 Flash a good daily driver AI model for many use cases.
OpenAI released GPT 5.2 Codex, the specialized coding-optimized AI model based on GPT-5.2 and built for professional software engineering and complex coding. GPT 5.2 Codex supports agentic coding and terminal workflows, and its extended context of up to 400K token inputs with native context compaction enables large repository development and debugging. The model scores SOTA on benchmarks such as SWE-Bench Pro (56.4%) and Terminal-Bench 2.0 (64.0%), just ahead of GPT-5.2 itself, while OpenAI touts its skill in cybersecurity tasks based on various benchmarks. GPT‑5.2-Codex is available in OpenAI Codex interfaces for paid ChatGPT users, with API access coming soon.
NVIDIA announced the Nemotron 3 family of open AI models and released Nemotron 3 Nano, featuring 30B total parameters with 3B active parameters at inference. Nemotron 3 Nano offers excellent performance with high inference speed and low cost thanks to using a hybrid Mamba-MoE architecture and a robust training pipeline. As we shared in “Nemotron 3 Nano and Apriel-1.6-Thinker Advance Open Local AI,” Nvidia also released the training data, training recipes, and technical reports to the community, providing open access to large-scale AI development resources. This model can therefore be the base for highly efficient fine-tuned AI models.
OpenAI launched GPT Image 1.5, an updated image generation and editing model that offers higher quality, faster inference (four times faster), and lower cost (20% cheaper) than the original GPT Image model. GPT Image 1.5 supports fine-grained control over specific image regions and edits, and its text rendering is to the point of accurately reproducing a detailed page of text in an image. Its ability to easily recast consistent characters into new scenes makes faking photos easy.
OpenAI also released an updated ChatGPT Images, the Images feature within ChatGPT, powered by GPT-Image-1.5 for all users. GPT-Image-1.5 can be accessed with the updated Images in ChatGPT and is also available via API, where it can be used in third-party interfaces.

Xiaomi launched MiMo V2, a powerful and fast open-source hybrid thinking AI foundation model. MiMo V2 performs at the level of Kimi K2 and DeepSeek V3.2 Thinking on reasoning benchmarks, getting 73.4% on SWE-Bench verified and 83% on GPQA Diamond. Yet Xiaomi claims it is high-speed (150 tokens/second) and costs only $0.1/M input tokens and $0.3/M output tokens. Xiaomi’s innovations in developing MiMo V2 include using a hybrid attention architecture that interleaves sliding-window and full attention, plus multi-token prediction for faster inference.
xAI unveiled the Grok Voice Agent API, a voice AI service designed to power real-time voice interactions that include integrated world knowledge and live tool calling. Developers can use it to build low latency voice-enabled agents with broad knowledge capabilities. Grok Voice Agent API ranks number one on Big Bench Audio. It is currently deployed in Tesla vehicles for native voice commands and live information access.
Black Forest Labs announced FLUX.2 [max] text-to-image and image editing model. FLUX.2 [max] is BFL’s highest quality model to date, improving over FLUX.2 [pro] with up to 10 reference images for consistent character generations and other enhancements. It ranks third on Artificial Analysis leaderboard behind Nano Banana Pro and GPT-Image 1.5.
In a related update, FLUX.2 Pro is now integrated into Adobe Photoshop as an enhanced generative fill model option, providing expanded model support for generative editing workflows inside Photoshop.

Kling AI Unveils Enhanced Motion Control in VIDEO 2.6, providing more precise action capture and improved controllability of motion dynamics in generated clips. Kling AI also launched advanced Voice Control in VIDEO 2.6, aimed at improving voice consistency and enabling custom voice behavior. This feature is part of Kling’s audio-enabled video workflow and includes better lip sync behavior. The pieces are in place for AI generated audio-video clips of convincing fidelity.
Google unveiled FunctionGemma, an open-source model fine-tuned for function calling and on-device inference on edge devices. FunctionGemma is intended for local automation tasks and serves as a strong base for creating customized, fast, private, local agents that translate language into executable actions. It is a 270 million parameter open-source model that requires only 500 MB of RAM, enabling it to run on mobile devices and browsers without cloud dependencies.
Google Labs introduced CC, an AI agent for personalized Gmail briefings, aimed at helping users with email workflows. With CC, users can manage and understand what’s happening in their inbox and get personalized briefings. CC is hosted on Google Labs and available via waitlist.
Apple Music added a ChatGPT integration that allows users to create playlists through conversational prompts. This user-facing feature turns chat instructions into playlist generation. In a Substack post, OpenAI’s head of product Fidji Simo positions this as one of many “Apps in ChatGPT” that will be brought to users, creating more dynamic AI experiences.
Mistral AI released Mistral OCR 3, a smaller AI model for Optical Character Recognition (OCR). OCR 3 extracts interleaved text and embedded images from PDFs and images into markdown enriched with HTML tables. Mistral reports a 74% win rate for OCR3 over OCR 2 on internal benchmarks. It is tuned for difficult cases like handwritten notes, complex forms, low quality scans, and dense tables.
Zoom launched AI Companion 3.0 with agentic workflows, an AI agent update that adds more agentic workflows to turn meeting content into insights and actions. The AI Companion turns summaries into task execution assistance across Zoom products, leveraging third-party AI models to support tasks.
Manus released Manus 1.6 Max and announced support for mobile app development and a new Design View feature. Manus describes Manus 1.6 Max as their most powerful AI agent yet, with a new core agent architecture to handle more complex workflows and higher one-shot success rates. The “Design View” feature supports image creation/visual outputs.
Google announced that Gemini Deep Research can now generate visualizations, including diagrams, illustrations, charts, and schematics into reports:
Deep Research can go beyond text to generate rich, visual reports complete with custom images, charts and interactive simulations.
OpenAI announced an AI chat branching feature on iOS and Android. The update is a UX feature that lets users branch or fork a conversation thread to explore alternate directions.
DoorDash launched an AI-powered social app called Zesty that uses AI to help people discover nearby restaurants and share recommendations socially. Zesty has a discovery feed plus social features (following, sharing, posting) with AI-driven personalization.
Alibaba announced Qwen Code v0.5.0, with VS Code integration and native TypeScript SDK, positioning it as a more usable coding/developer experience.
Meta unveiled SAM Audio, a unified multimodal AI model to separate and manipulate sounds using text or visual prompts. Just as its Segment Anything Model (SAM) can segment visual elements of an image, Meta’s SAM Audio can separate sounds from a sound source using text prompts; for example, a “dog barking” text prompt will output only a dog bark from a merged sound source. This is useful for a variety of audio editing tasks, such as noise removal or music production, where prompts guide which sounds to isolate or modify. Meta published the research behind SAM Audio on Meta’s AI blog.
Allen Institute for AI released Bolmo, an AI model that tokenized at the byte-level and reaches parity with similar-sized models using standard tokenization. By processing inputs at the byte level, including images, audio, and text, BOLMO’s architecture may open up new avenues for universal data processing and content understanding, broadening multimodal capabilities. The technical report “Bolmo: Byteifying the Next Generation of Language Models” explains further details of the architecture and training for Bolmo.
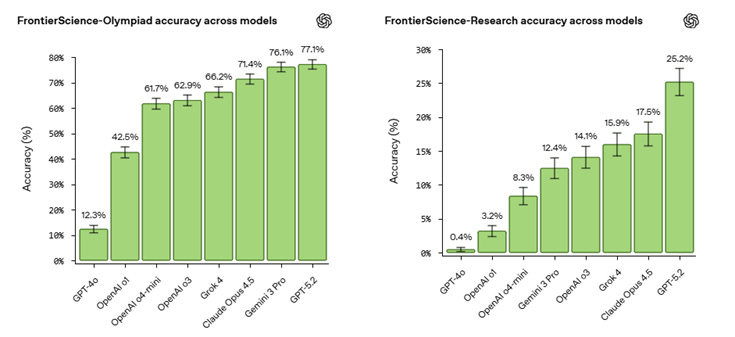
OpenAI published the FrontierScience benchmark, an evaluation focused on expert-level scientific research tasks spanning physics, chemistry, and biology. The benchmark is composed of evaluation questions that measure both Olympiad-style scientific reasoning capabilities and real-world scientific research abilities. The announcement frames it as a way to measure model capability on research-relevant scientific work. The benchmark description and rationale are provided in OpenAI’s post.
OpenAI published results claiming GPT-5 boosted wet lab molecular cloning efficiency 79-fold.
OpenAI described how its model was applied to wet-lab biological research workflows, including molecular cloning protocols, and obtained significant measured efficiency improvements, accelerating biological research. The research summary is hosted on OpenAI’s website.
We had a full plate of AI releases and AI research news thanks to the pre-Christmas AI release rush, so we will skip other AI news items. Enjoy the new AI goodies this holiday season!