

A new benchmark puts top models like GPT-5.4 and Claude Opus 4.6 to work on the kinds of tasks junior investment bankers handle every day. Not a single output was deemed ready to send to a client. Still, more than half of the bankers said they’d use it as a starting point.
A research team at Handshake AI and McGill University has released BankerToolBench, an open-source benchmark that tests AI agents against the typical workflows of junior investment bankers.
Handshake AI is the business arm of the career platform Handshake, which places vetted academics and professionals inside AI labs to help train and evaluate their models. After running nine current top models through the test, the verdict from the bankers involved is blunt: none of the outputs are fit for client use.
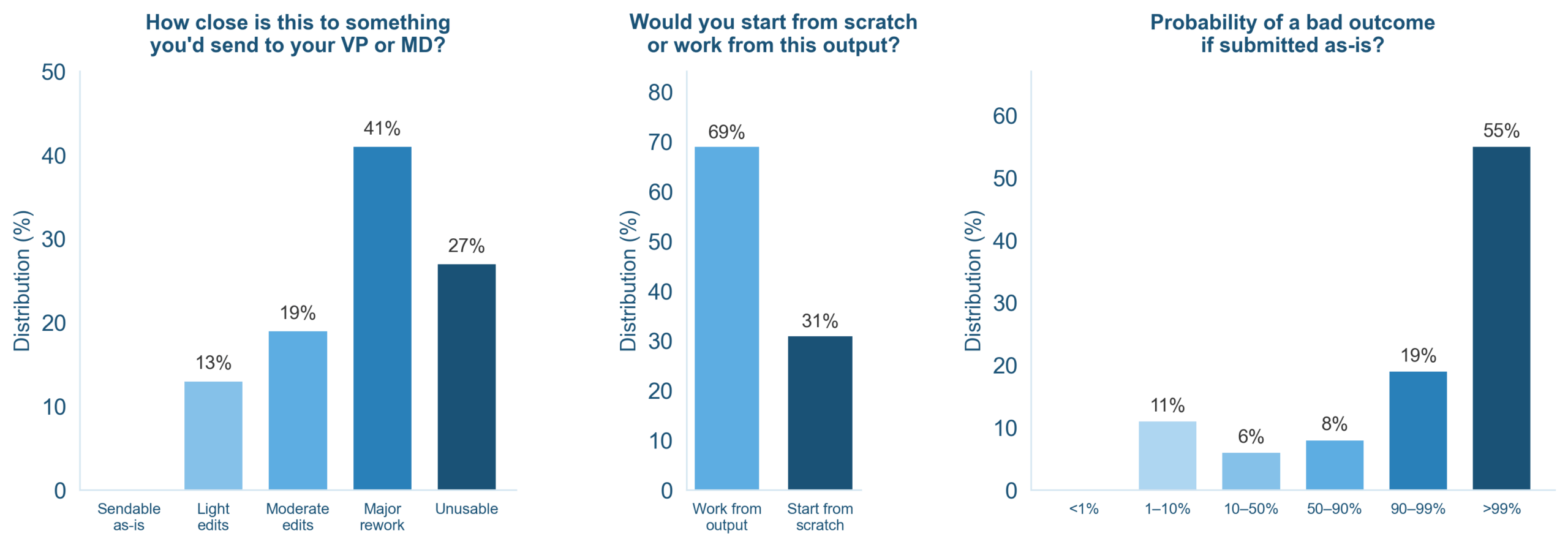 Bankers said 41 percent of AI outputs need a major rework, and 27 percent are completely unusable. Just 13 percent could pass with light edits, and not a single result was rated ready to send as is. | Image: Lau et al.
Bankers said 41 percent of AI outputs need a major rework, and 27 percent are completely unusable. Just 13 percent could pass with light edits, and not a single result was rated ready to send as is. | Image: Lau et al.
The team enlisted around 500 current and former investment bankers from firms including Goldman Sachs, JPMorgan, Evercore, Morgan Stanley, and Lazard. Of those, 172 designed the tasks themselves, logging more than 5,700 hours of work. Each of the 100 tasks took a human banker an average of five hours, with some running up to 21 hours.
BankerToolBench grades the actual deliverables a junior banker would hand to a supervisor: Excel financial models with working formulas, PowerPoint decks for client meetings, PDF reports, and Word memos.
The agents have to dig through data rooms, pull from market data platforms like FactSet and Capital IQ, and parse SEC filings. According to the paper, a single task can trigger up to 539 calls to the language model, with 97 percent tied to tool use or code execution.
Each deliverable is checked against a banker-designed rubric averaging 150 individual criteria. The criteria span six areas, including technical correctness, client readiness, compliance, auditability, and consistency across files.
Grading is handled by an AI verifier the authors built called Gandalf, based on Gemini 3 Flash Preview. It agrees with human reviewers 88.2 percent of the time, slightly above the 84.6 percent agreement rate between two human reviewers.
GPT-5.4 leads, but it’s not close to passing
The team tested GPT-5.2, GPT-5.4, Claude Opus 4.5 and 4.6, Gemini 2.5 Pro, Gemini 3.1 Pro Preview, Grok 4, and the open-source models Qwen-3.5-397B and GLM-5. GPT-5.4 came out on top but still failed nearly half the criteria. Just 16 percent of its outputs cleared the bar where bankers would accept them as a useful starting point. Require three consistent runs, and that figure drops to 13 percent.
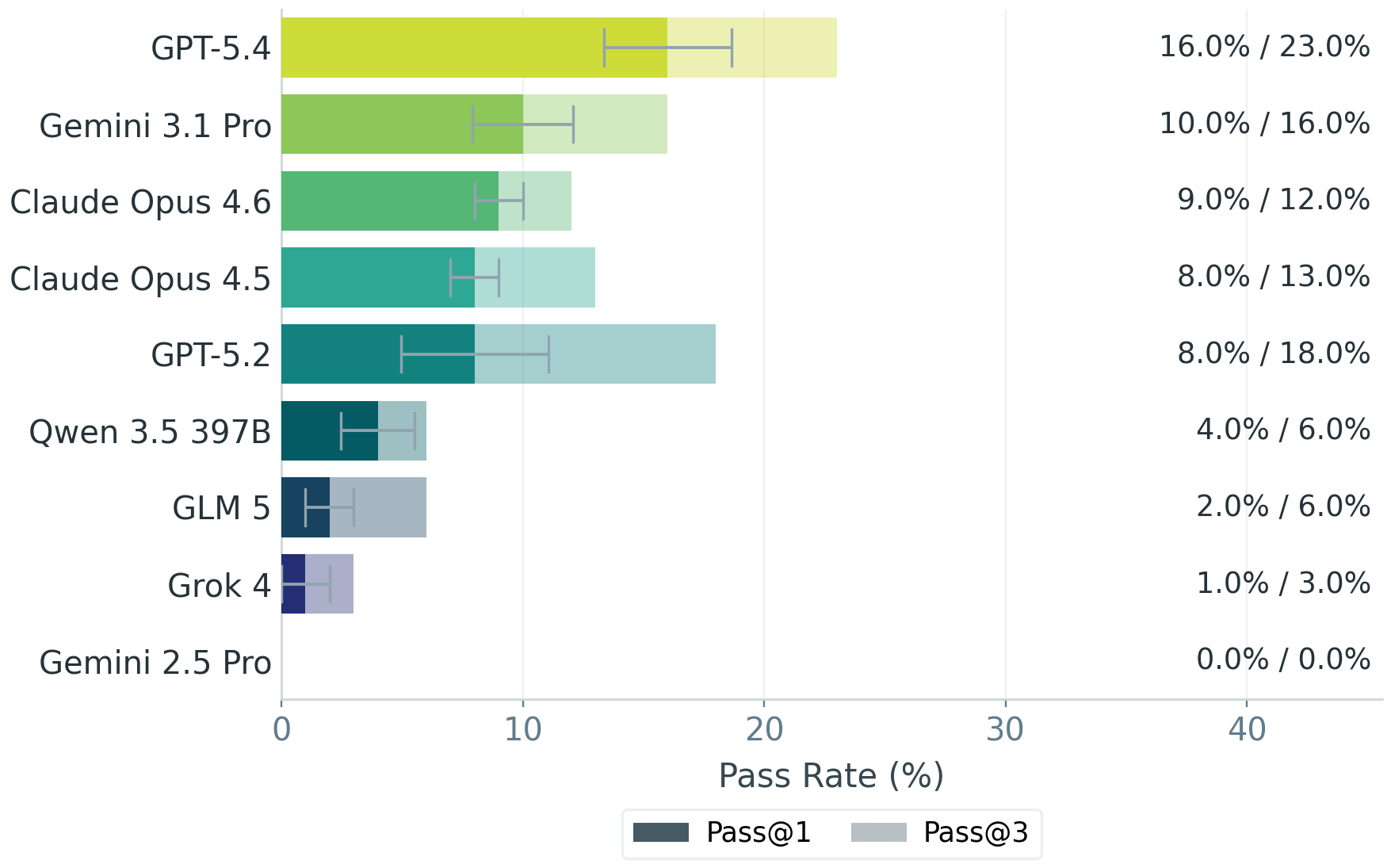 Bankers rated only 16 percent of GPT-5.4’s outputs as a useful starting point. Require three consistent runs and the figure falls to 13 percent. Gemini 2.5 Pro doesn’t pass a single task. | Image: Lau et al.
Bankers rated only 16 percent of GPT-5.4’s outputs as a useful starting point. Require three consistent runs and the figure falls to 13 percent. Gemini 2.5 Pro doesn’t pass a single task. | Image: Lau et al.
Not a single output from any model was deemed ready to submit as is. With GPT-5.4, just 2 percent of tasks cleared every critically weighted criterion. With Gemini 2.5 Pro, that figure was zero.
Pretty on the outside, broken underneath
Claude Opus 4.6’s outputs look polished at first glance, according to the researchers. But the Excel models reveal a fundamental flaw: most of the key numbers are hardcoded as fixed values rather than calculated through formulas. That’s a dealbreaker in investment banking, the paper notes, because it makes scenario analysis impossible. Change the purchase price in the model, and nothing updates. Claude Opus 4.5 had the same problem.
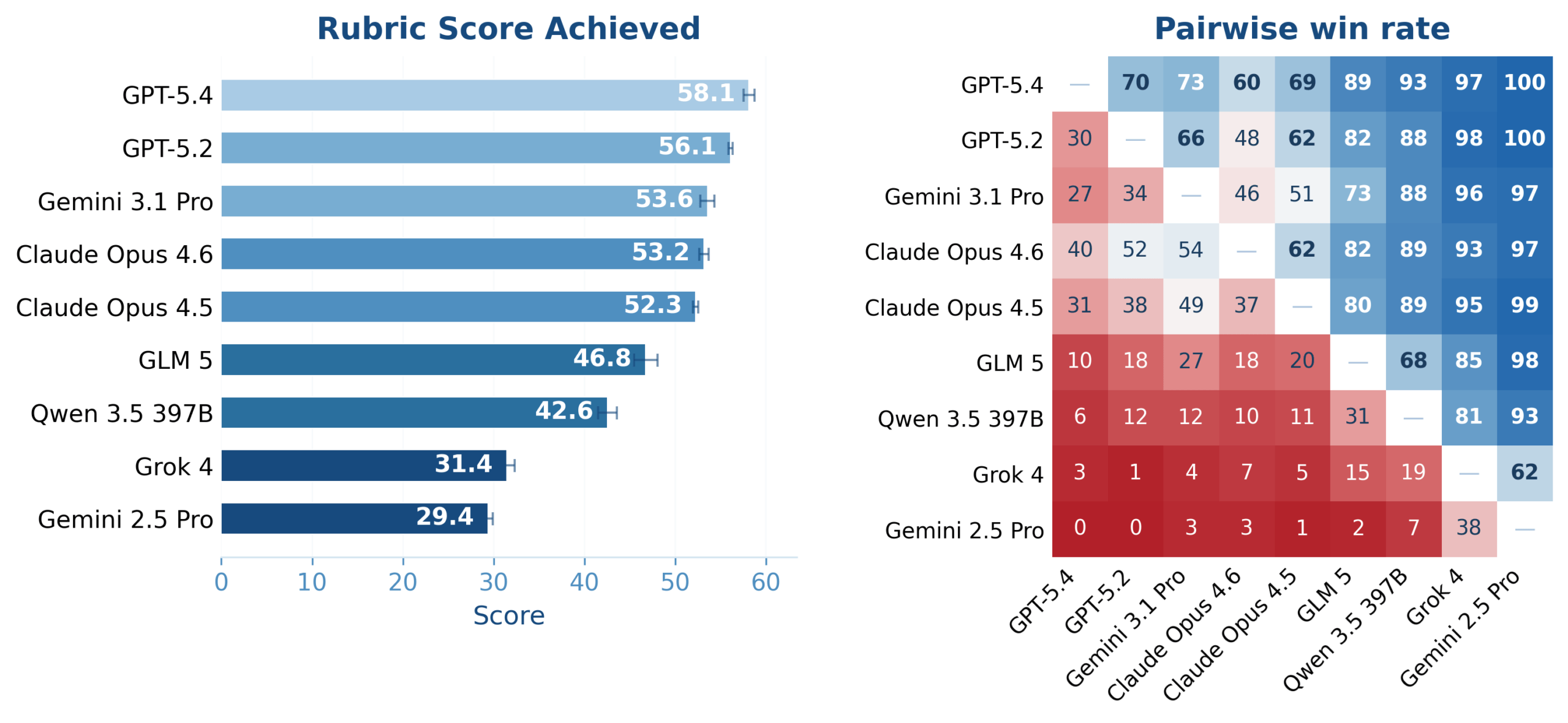 GPT-5.4 scored 58.1 out of 100 overall and beat GPT-5.2 in 70 percent of head-to-head task comparisons. Claude Opus 4.6 and Gemini 3.1 Pro are nearly tied, while Grok 4 and Gemini 2.5 Pro trail far behind. | Image: Lau et al.
GPT-5.4 scored 58.1 out of 100 overall and beat GPT-5.2 in 70 percent of head-to-head task comparisons. Claude Opus 4.6 and Gemini 3.1 Pro are nearly tied, while Grok 4 and Gemini 2.5 Pro trail far behind. | Image: Lau et al.
An analysis of GPT-5.4’s agent trajectories surfaces four recurring failure modes. The most common, at 41 percent, are bugs in code and formula generation. The agents call python-pptx functions that don’t exist, and rather than fixing the underlying issue, they simply delete the broken line.
In 27 percent of cases, the business logic breaks down, such as adding cost synergies to the revenue line instead of to costs. Another 18 percent of errors stem from aborted data queries. And in 13 percent of cases, agents fabricate missing numbers and pass them off as sourced.
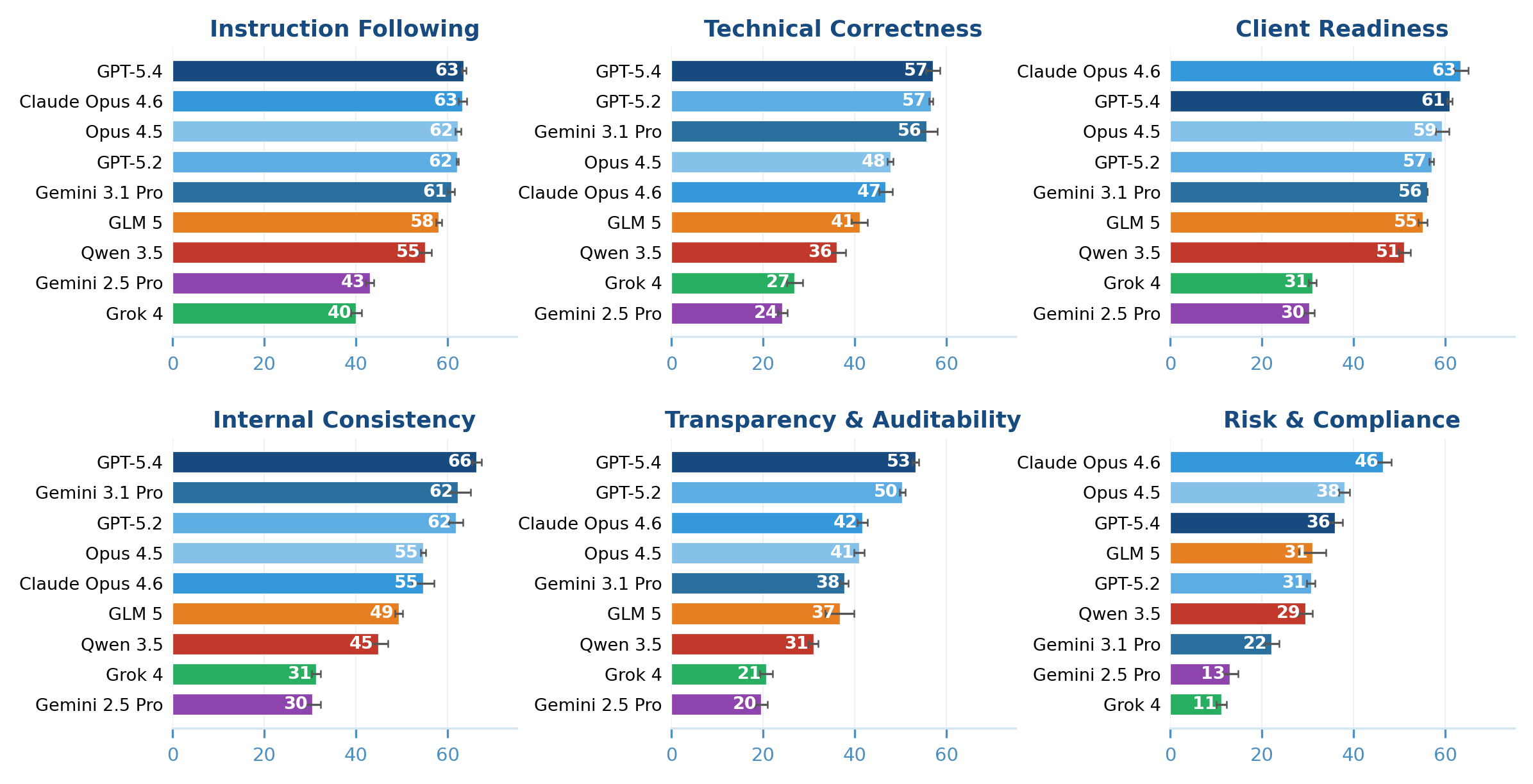 Claude Opus 4.6 leads on Client Readiness with 63 points and on Risk & Compliance with 46. But the model scored just 47 on the decisive Technical Correctness category, where GPT-5.4 took the lead with 57. | Image: Lau et al.
Claude Opus 4.6 leads on Client Readiness with 63 points and on Risk & Compliance with 46. But the model scored just 47 on the decisive Technical Correctness category, where GPT-5.4 took the lead with 57. | Image: Lau et al.
Subtle errors that slip through
The examples in the paper illustrate how subtle these failures can be. In one generated deck, the verifier flags a revenue figure of $189.5 billion on one slide and $201.0 billion on the next, both covering the same period.
In another case, the agent uses Netflix red as an accent color even though the bank’s style guide mandates a uniform blue. In a competitive analysis for a pharma deal, an agent fabricated specific clinical trial data after coming up empty in the SEC database.
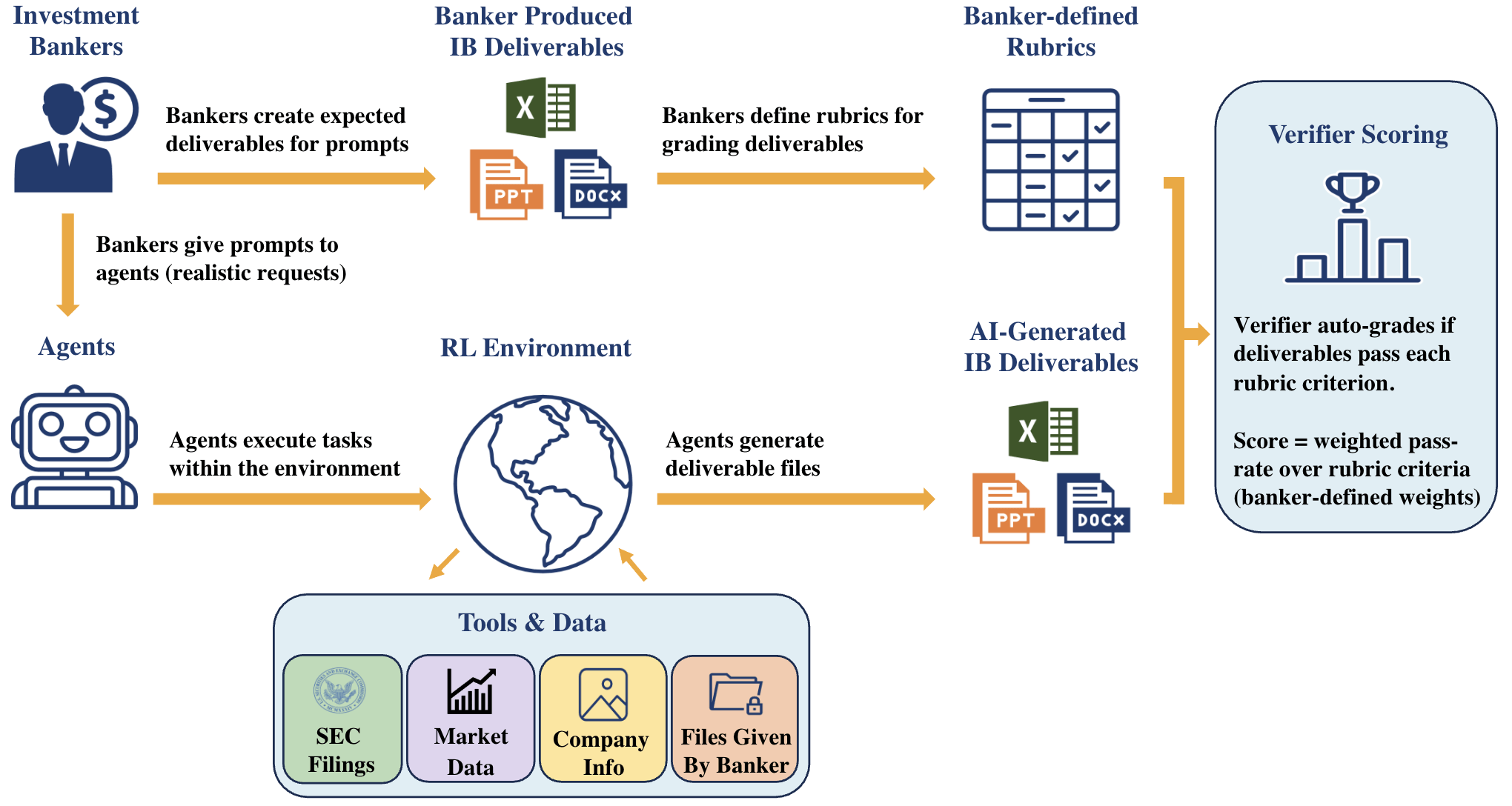 How BankerToolBench works: bankers write realistic prompts, produce sample deliverables, and define grading rubrics. AI agents tackle the same prompts in a sandbox with SEC filings, market data, and company info, and a verifier scores the resulting Excel, PowerPoint, and Word files against the rubrics. | Image: Lau et al.
How BankerToolBench works: bankers write realistic prompts, produce sample deliverables, and define grading rubrics. AI agents tackle the same prompts in a sandbox with SEC filings, market data, and company info, and a verifier scores the resulting Excel, PowerPoint, and Word files against the rubrics. | Image: Lau et al.
The models generally perform better on PowerPoint tasks than on Excel work. The toughest tasks fall in debt capital markets, merger models, and capital structure tables. The team attributes some of the shortfall to missing domain knowledge. When tasks are enriched with the kind of context bankers take for granted, scores rise significantly.
A training tool, too
BankerToolBench can also be used for reinforcement learning, according to the authors. In experiments with Qwen-3-4B and 32B, the Dr. GRPO and DPO methods boosted benchmark performance by a factor of five to thirteen, though from a very low baseline.
The team flags several limits: the benchmark is US-focused, lacks confidential deal information, and doesn’t capture the iterative teamwork inside a real bank. Even so, the authors call it one of the most detailed tests yet of whether AI agents can handle demanding knowledge work. For now, the answer is no. The full benchmark, including data, rubrics, and verifier, is publicly available.
The findings line up with other recent research. A Vals.ai study conducted with a globally systemic bank found that OpenAI’s o3 hit just 48.3 percent accuracy on financial analysis tasks. UC Berkeley research concluded that the teams getting agents to work in production are relying on simple, tightly controlled setups with few steps. And an analysis from Carnegie Mellon and Stanford argues that agent development has focused too narrowly on coding tasks, leaving economically important fields like management, law, and finance largely absent from benchmarks.
Meanwhile, AI labs like Anthropic are working on exactly the weaknesses BankerToolBench exposes. Anthropic recently introduced a feature that lets Claude switch on its own between Excel and PowerPoint, and Cowork plugins now pipe market data services like FactSet, MSCI, and LSEG directly into the workflow.