
![[OC] English vocabulary: learners vs. native speakers](https://www.byteseu.com/wp-content/uploads/2026/04/op2y9n0obltg1-905x1536.png "[OC] English vocabulary: learners vs. native speakers")
The data are based on 34,000 learners and native speakers who took the vocabulary test.
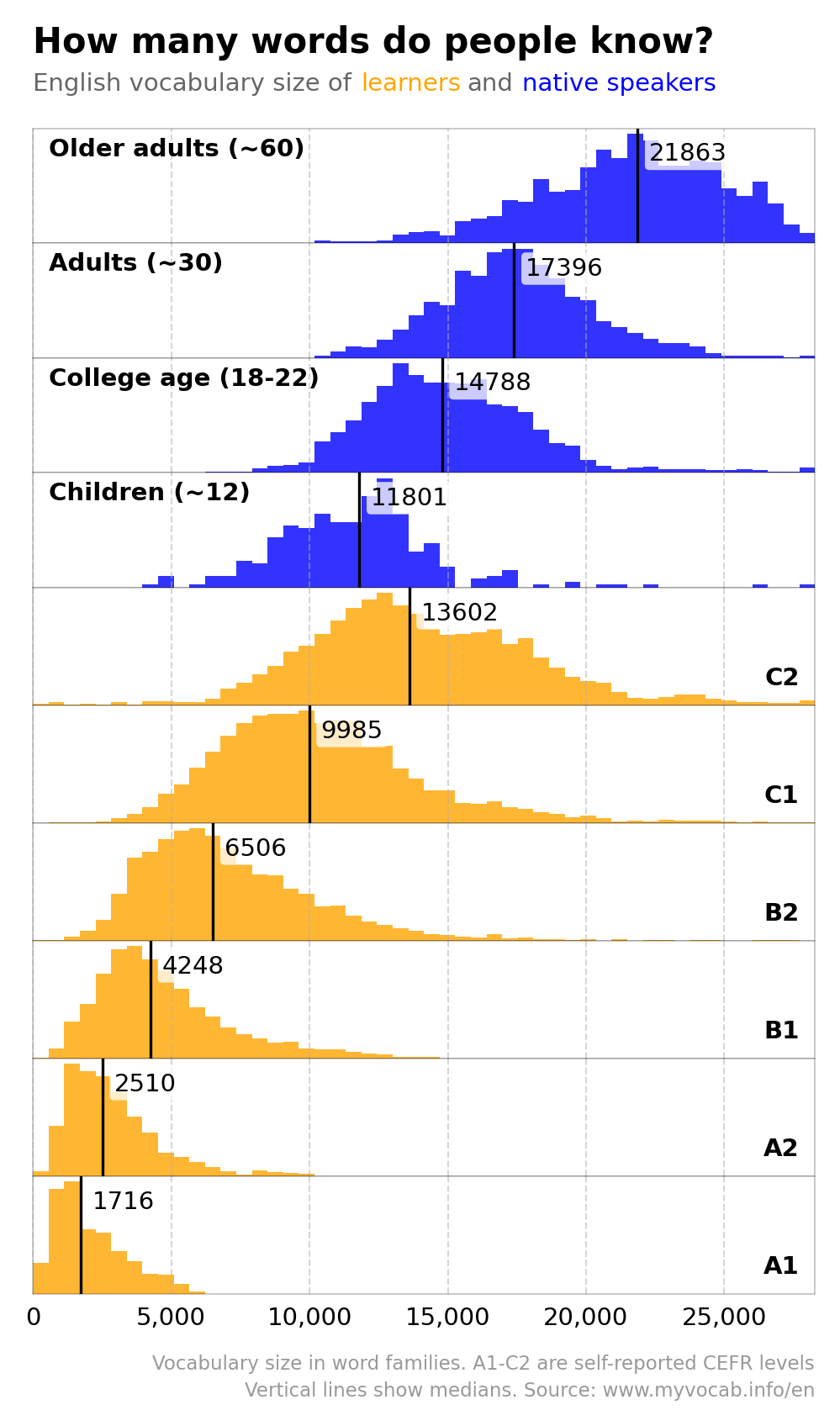
A1-C2 are CEFR levels, a common classification of proficiency among language learners. A1-A2 are beginners, B1-B2 — intermediate, C1 — advanced learners, and C2 is supposed to be a native-speaker level (and achieved by very few learners). The levels were self-reported.
The counting units are word families (so limit, limitless, unlimited are counted as a single unit). The full reference lexicon is 28k word families.
Based on the data, a C1 is below the average middle-schooler, and a C2 is at about the level of a college-age native speaker. This is only if we force them onto the same one-dimensional scale, of course, because in reality the composition of their vocabulary is quite different.
Posted by RevolutionaryLove134
32 Comments
Cool test, fun to try. I landed exactly where I should (C2 14200 or 14800 words).
And very cool to see how those levels actually compare to native speakers 😎
I’m curious about those kids that showed up as the outliers with huge vocabularies. I’m guessing they’re book nerds.
I wonder how much of this is biased from the fact that more recent generations have a more limited vocabulary in general. In which case, it would be less about age and more about specific generation.
Seems accurate, I can say my dad has a D2 Spanish level 😂 he be like creating new words out of thin air HAHAH
6 classes from A1 to C2, and then there’s freakin’ Shashi Tharoor.
Interesting I feel as if my vocabulary has actually shrank since college… i went from trying to sound smart to trying to make everything as simple as possible for coworkers
That is an interesting and cool way to test. I got 18500 words with it as my second language which sounds plausible. I saw in the results afterwards that there were some fake words introduced in the test – I am impressed that they were well enough hidden that I can’t imagine which ones it would be.
Does this show that you learn more words as you grow up or does this show that the more literate you are the longer you live
Do people really expand their vocabulary much between ages 30 and 60? Hell, I feel even an increase between college age and 30 is surprising.
Or is it a generation issue?
Why do older people seem to have much bigger vocabularies? Older people tend to have less formal education.
I suspect there’s some kind of selection bias at work here. I suppose if you are taking a voluntary vocab test in the first place, you’re more likely to be the kind of person who has a large vocabulary, ie someone who loves reading. Which you can do better if you’re more likely to be retired.
So I can struggle & grind my way up to C2, only to be on par with a child?
Interesting. 19000 words; non native English speaker.
I’m quite curious how the natives would stack up against immigrants who came as late children/early teens. Technical not native but immersed in the same environment with native speakers since school age.
Yeah I feel like the non-native population is heavily biased, like you would only end-up on this website if you frequent the anglosphere, so your level is generally far above the “general population” of non-natives.
I feel like there could be a sampling bias with this test? Those who are likely to take a vocab quiz voluntarily are also likely to be passionate about vocab. I scored median for my group which is expected, but I doubt that 50% of people in my bracket actually know the definition of a word like “loquacious”.
Nice visualisation of how difficult it is to become a native speaker. C2 being on the same vocabulary level as a child does not surprise me. You do not learn many everyday words in books and online, and immersion is a big contributor to language proficiency.
Some of the fake words are a single letter off real words (ventrel v. ventral) Not sure if this is intentional but my vocabulary is significantly larger than the list of words I’m certain about the exact spelling which caused me to “recognize” a couple non-words as words
The bimodal distribution in the learners is really interesting, what could be happening?
Could be interesting to add the native language / place if education to see how different countries rank.
Landed at 19,100 as non-native English speaker albeit collaborating with clients/partners from US, Australia and UK over the last 15 years. Test seemed weirdly overindexed on some religious/church related terms. Overall there were hardly any words that are used today except in literature.
Very interesting. To add a bit to the discussion, it’s a tough comparison because as a Frenchman I know loads of words from French that are still fairly common for us, but that most English speakers rarely use. A few examples are limpid, neophyte, gregarious, and obstinate. When I use words like that, a lot of English speakers do not fully understand them, unless they are older, maybe 50y+
It goes both way by the way, words like “procrastiner” in French wasn’t very used till the last two decades while very common in English
25k. Mostly due to playing dark fantasy games where they use fancy words and reading good novels
On the test, how are we intended to answer if we know the root word, but not the specific one presented? For example, I know the word Bursar, but was presented with Bursary, which I haven’t seen, so I marked it unknown. I was confident I could’ve defined it, but played it safe and erred on the side of caution.
My problem is I understand 20,000 words but only use same 200 when speaking.
Interesting fact – in Russian native speakers plateau reaching in 4-fold vocabulary size then English ~70-80 000 words.
Note for reference that English contains between 500,000 and 1,000,000 words depending on what counts as a word. (Is teach, teaches, teacher, teachable, teaching one word or five words?)
When you ask a Dutch person whether they can speak English they may reply “a little”, which means they can carry on a conversation with you or “yes”, in which they will be correcting your grammar. 😄
I’m non-native… and I think that if your first language is Italian/French (maybe Spanish/Portuguese, too) you have a clear advantage: lots of “hard” words in the test have clear French or Latin etymologies
This is the research these statistics for native speakers are based upon. In the paper the authors cite the difference between recognizing a word and being able to use that word as a limiting factor in their experiment. Due to the large number of language families, lemmas, it is easier to recognize that a string of letters is a word that to use it accurately in a sentence. Most English learners can probably use every word they recognized.
https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2016.01116/full
I think this test is very interesting but I’m also a little wary of the data.
1. i tried the test a few times and got pretty different results. I can’t see anything in the “how it works” page that indicates confidence intervals, but it feels like there’s still quite a lot of randomness (presumably a tradeoff for keeping the test short).
2. words often come in and out of use. There are an awful lot of words in the test that just aren’t in regular use any more. I also didn’t see any newer words (i.e. words pertaining to new technologies, media, etc), which is problematic. I can believe that older adults have larger vocabularies than younger adults, but this exacerbates that and also introduces a “I read old/faux old literature” bias.
3. I get the feeling that the test is trying to use rare/difficult words to ascertain overall level. That seems to be more prone to randomness. I was given a whole string of words that not only do I not know the meaning of, but I’ve never heard of, nor would I expect anyone that I know to have heard of them. Perhaps that’s happened because I correctly got a bunch of more common ones, but it would seem more sensible to me to test deeper at a lower level than start bandying around words not used since 1850.
4. Rare doesn’t equal difficult. “Juvenescence” is a word I’ve never heard of, and it has an almost flatlining ngram, but it’s meaning is completely obvious. Conversely “moot”, “offing”, and “shrift” are all relatively common words (used exclusively in idioms) which actually have quite obscure meanings on their own, which relatively few people would know.
5. Usage differs geographically. Words like “prorogue”, “pupillage”, and “conveyancing” are all more than 10x as common in British English than in American English.
6. obviously the data is skewed ridiculously by selection bias – the people taking the test are in no way representative of the general population. If you want serious data you need to get a serious sampling method.
Could you please add members of each federal branch (executive, legislative and judicial) to this dataset? Now that would be really interesting if available.
I don’t understand what I’m seeing. the x axis is number of words people know, but what is the y axis?