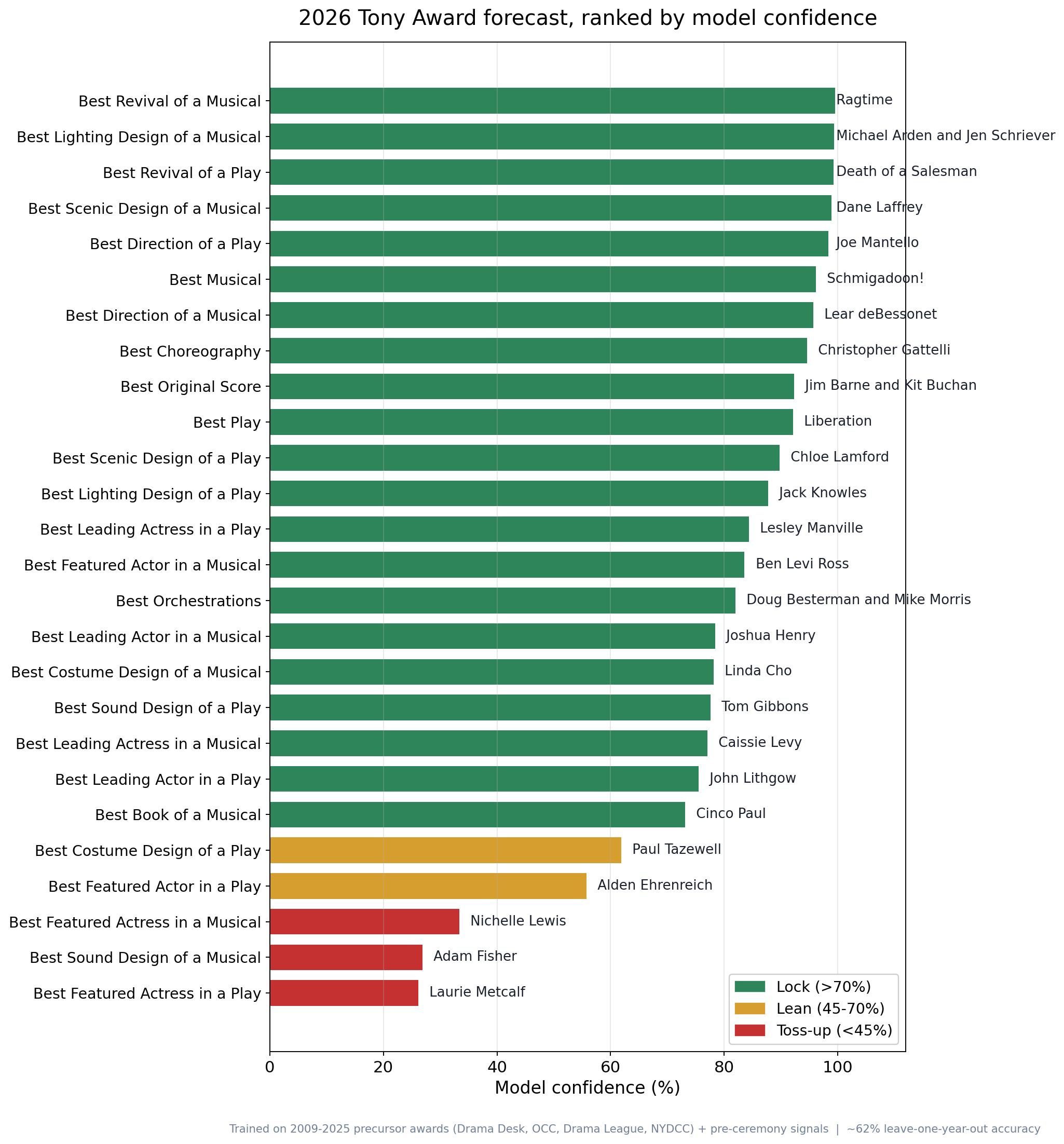
[OC] My model’s predictions for the 2026 Tony Awards, built from precursor-award results and 16 years of data
Posted by dsbuddy

![[OC] My model's predictions for the 2026 Tony Awards, built from precursor-award results and 16 years of data](https://www.byteseu.com/wp-content/uploads/2026/06/m3248xkbb55h1-1429x1536.png "[OC] My model’s predictions for the 2026 Tony Awards, built from precursor-award results and 16 years of data")
[OC] My model’s predictions for the 2026 Tony Awards, built from precursor-award results and 16 years of data
Posted by dsbuddy
5 Comments
**Source:** Tony + precursor award results (Drama Desk, Outer Critics Circle, Drama League, NY Drama Critics’ Circle) for 2009-2025, via Wikipedia, plus each show’s pre-ceremony reviews, commercial status, and predicted-odds standing.
**Tools:** Python for the model (a naive Bayes weighted vote), matplotlib for the charts.
**Method:** Every input is time-locked to what was known before each ceremony. Accuracy is measured leave-one-year-out (train on every season but one, predict the held-out year): ~62% across all 26 categories vs. ~54% for a “pick whoever won the most precursors” baseline. Bars are colored by confidence tier.
**Code + data + more charts:** [https://github.com/dsbuddy/tony-awards-predictor](https://github.com/dsbuddy/tony-awards-predictor)
Testing your model on poly market? Even for a few bucks?
The made a Schmigadoon musical? That seems redundant.
What’d you feed in as the features for the model? And how’d it test on the test sets?
Perfect choice of model. Great job OP